

1. 서 론
2. 이론적 배경
2.1 물리기반 산불 확산 예측 모델: FARSITE
2.2 생성적 적대 신경망(Generative Adversarial Network)
3. CGAN 기반 산불 확산 예측 프레임워크
3.1 CGAN 기반 예측 모델 개요
3.2 학습 데이터 구축 및 전처리
3.3 학습결과
4. 수치예제: 기존 AE기반 산불 확산 예측모델과의 비교
5. 결 론
1. 서 론
산불은 발생 시 산림 자원의 직접적인 파괴를 넘어 사회기반시설의 손상, 막대한 재산 피해, 인명 사고 및 이재민 발생 등 복합적인 2차 피해를 초래하는 재난이다(Chen et al. 2024). 이러한 피해의 여파는 산불 진화가 완료된 이후에도 생태계 파괴와 지역 사회의 경제적 손실 등 장기간 지속되는 경향을 보인다.
최근 국내 안동 산불 사례는 이러한 위험성을 여실히 보여주는데, 당시 화재는 매우 빠른 속도로 확산되어 광대한 산림을 소실시켰을 뿐만 아니라 심각한 대기 오염과 민가 피해를 동반하였다(Kim et al. 2024). 더욱이 최근 기후 변화의 영향으로 전 세계적으로 산불의 발생 빈도와 규모가 급격히 증가하고 있어(Carvalho et al. 2025), 산불 발생 초기에 확산 경로를 정확하고 신속하게 예측하여 골든타임 내에 효과적인 진화 전략을 수립하는 것이 그 어느 때보다 중요해졌다.
산불 확산 메커니즘에는 지형, 기상, 연료 등 다양한 환경적 요인이 복합적으로 작용하며 이들 요인의 불확실성으로 인해 기존에는 FARSITE와 같은 물리 기반 시뮬레이션 모델이 예측의 표준으로 활용되어 왔다(Finney 1998). FARSITE는 타임스텝마다 파동 전파 이론(Wave Propagation Theory)을 적용하여 산불의 확산 경로와 속도를 계산하며, 연료 유형, 지형의 고도 및 경사, 풍속과 기온 등 정밀한 변수를 반영한다. 이 모델은 다른 방법론에 비해 상대적으로 높은 물리적 신뢰도와 정확도를 제공한다는 장점이 있다. 그러나 물리 기반 예측모델은 광범위한 지역을 고해상도로 시뮬레이션할 때 막대한 계산 자원을 필요로 하며, 입력 데이터 수집과 처리 과정이 복잡하다는 한계를 지닌다. 이로 인해 결과도출까지 발생하는 지연시간은 신속한 의사결정이 필수적인 실제 재난 상황에서 즉각적인 대응을 어렵게 만드는 주요 요인이다(Sullivan 2009). 또한, 실시간으로 급변하는 기상 조건과 산불의 동적 확산 양상을 시뮬레이션에 즉각적으로 반영하지 못할 경우, 실제 상황과 예측 결과 사이에 상당한 괴리가 발생할 수 있다.
이러한 물리 기반 예측모델의 한계를 극복하기 위해 데이터 기반의 딥러닝 기법, 특히 합성곱 신경망(Convolutional Neural Network, CNN)을 활용한 연구가 활발히 진행되어 왔다(Shadrin et al. 2024). 그중에서도 Fig. 1과 같은 오토인코더(Autoencoder, AE) 구조는 산불 확산 예측 시 딥러닝을 활용한 대표적인 방법론으로 자리 잡았다
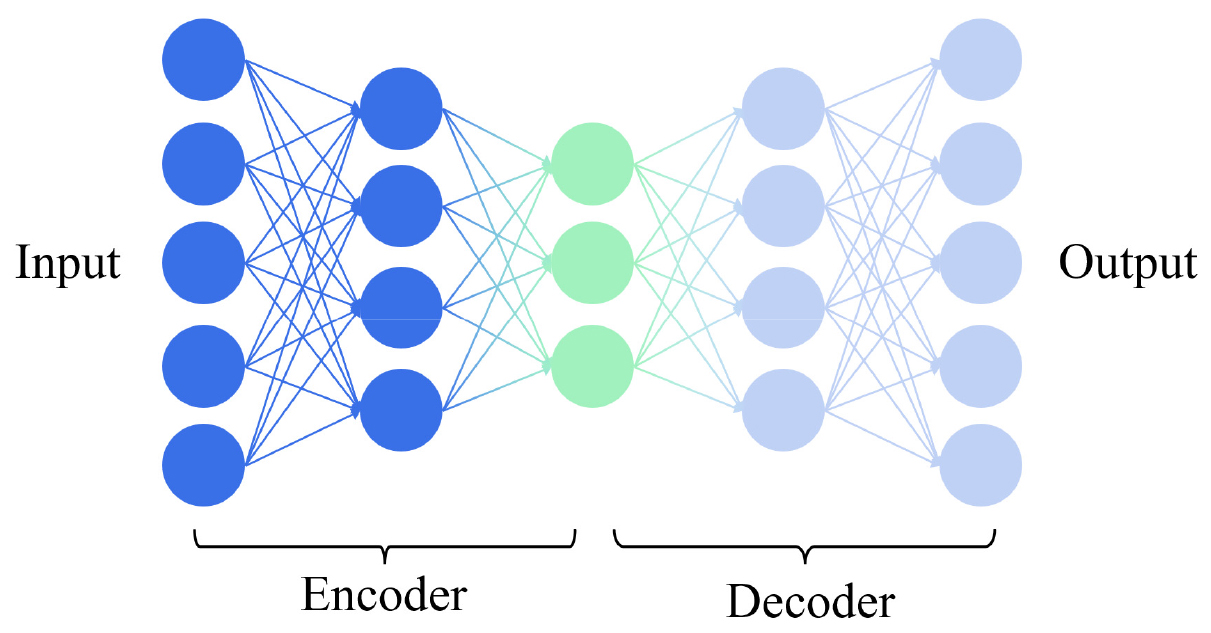
오토인코더는 고차원의 산불 확산 이미지를 입력받아 인코더(Encoder)를 통해 저차원의 잠재 공간(Latent Space)으로 압축하여 핵심적인 공간적 특징(Spatial Features)을 추출하고, 이를 다시 디코더 (Decoder)를 통해 원래의 이미지 크기로 복원하는 과정을 거친다(Bank et al. 2023). 그러나 이러한 오토인코더 기반의 접근 방식은 대부분 입력과 출력 간의 픽셀 단위 오차(Mean Squared Error, Mean Absolute Error 등)를 최소화하는 것을 목표로 학습하기 때문에 복잡한 형태를 평균화하여 표현하는 경향이 있다. 이로 인해 예측된 산불의 확산 가장자리가 흐릿하게 생성되거나 산불 특유의 복잡하고 불규칙한 특징을 놓치는 한계가 발생한다. 또한 고정된 입력에 대해 항상 동일한 결과를 도출하는 결정론적 특성은 시시각각 변하는 산불의 확률론적 변동성을 충분히 반영하기 어렵다는 단점이 있다.
최근 컴퓨터 비전 분야에서는 생성적 적대 신경망(Generative Adversarial Network, GAN)이 이미지 생성 및 복원 분야에서 보다 뛰어난 성능으로 각광받고 있다. GAN은 실제 데이터와 유사한 결과를 생성하는 생성자(Generator)와 데이터의 진위여부를 판별하려는 판별자(Discriminator)가 상호 경쟁하며 학습하는 구조를 갖는다(Goodfellow et al. 2014). 이러한 적대적 학습 방식은 고해상도 이미지 생성이나 복잡하고 불규칙한 패턴을 학습하는 데 탁월하며 비선형적이고 예측 불가능한 산불 확산 양상을 모델링하는 데에도 매우 유용할 것으로 기대된다(Isola et al. 2017). 그럼에도 불구하고 아직 GAN을 산불 확산 예측에 직접적으로 적용한 연구는 드문 실정이다.
본 연구에서는 기본 GAN의 변형인 조건부 생성적 적대 신경망(Conditional Generative Adversarial network, CGAN)을 도입하여 산불 확산 예측 모델을 제안한다. 기존 GAN이 무작위성으로 인해 사용자가 원하는 특정 조건(기상, 지형 등)을 반영하기 어렵다는 단점을 보완하여 산불 발생 시점의 환경 변수를 조건(Condition)으로 입력받아 예측의 정확도와 제어 가능성을 높이고자 한다. 이를 위해 FARSITE 시뮬레이션을 통해 대규모 데이터셋을 구축하고, 제안 모델과 기존 AE 기반 예측모델의 성능을 정량적, 정성적으로 비교 분석함으로써 그 유효성을 검증하고자 한다.
2. 이론적 배경
2.1 물리기반 산불 확산 예측 모델: FARSITE
FARSITE는 미국 산림청(US Forest Service) 미소울라 화재과학 연구소(Missoula Fire Sciences Laboratory)에서 개발한 2차원 산불 확산 예측 시스템으로 현재까지 전 세계적으로 산불 관리 및 연구의 모델로 활용되고 있다. FARSITE는 파동 전파 (Wave Propagation) 이론을 산불 확산에 적용한 모델이다. 이 원리에 따르면 타오르는 불길의 가장자리에 있는 각 점은 독립적인 발화원이 되어 타원형의 소규모 화염(Wavelet)을 생성하고, 이들의 외곽선을 연결함으로써 다음 단계의 화재 확산 경계면 (Perimeter)이 형성된다. 사용자는 시뮬레이션을 위해 대상 지역의 지형(고도, 경사, 형상)과 식생(연료 모델, 수관율) 그리고 기상(풍속, 풍향, 기온, 습도, 강수량) 등 다양한 환경 변수를 입력해야 한다. FARSITE는 이러한 입력 데이터를 바탕으로 Rothermel의 표면 화재 확산식과 Van Wagner의 수관화 전이 모델 등 검증된 물리/경험식을 결합하여 각 격자(30 pixel per meter) 단위에서 연료의 수분 함량 변화, 열 방출량, 화염 길이 등을 정밀하게 계산한다(Rothermel 1972).
이러한 물리 기반 접근 방식은 산불 확산의 미세한 거동을 사실적으로 모사할 수 있다는 강력한 장점을 지닌다. 그러나 시공간 해상도를 높일수록 연산량이 기하급수적으로 증가하며, 방대한 입력 데이터의 전처리 과정이 복잡하다는 한계가 존재한다. 특히 국지적인 돌풍이나 급격한 연료 변화와 같은 실시간 현장 변수를 즉각적으로 시뮬레이션에 반영하기 어렵기 때문에 신속성이 요구되는 재난 대응 상황보다는 사후 분석이나 장기적인 방재 계획 수립에 주로 제한적으로 활용되어 왔다.
2.2 생성적 적대 신경망(Generative Adversarial Network)
생성적 적대 신경망(GAN)은 기존의 딥러닝 모델들이 주로 수행하던 데이터의 분류(Classification)나 회귀(Regression)를 넘어 학습 데이터의 확률 분포(Probability Distribution)를 근사하여 새로운 데이터를 생성(Generation)하는 프레임워크이다 (Goodfellow et al. 2014). GAN은 Fig. 2와 같이 서로 대립하는 두 개의 신경망인 생성자(Generator, G)와 판별자 (Discriminator, D)를 경쟁적으로 학습시킨다.
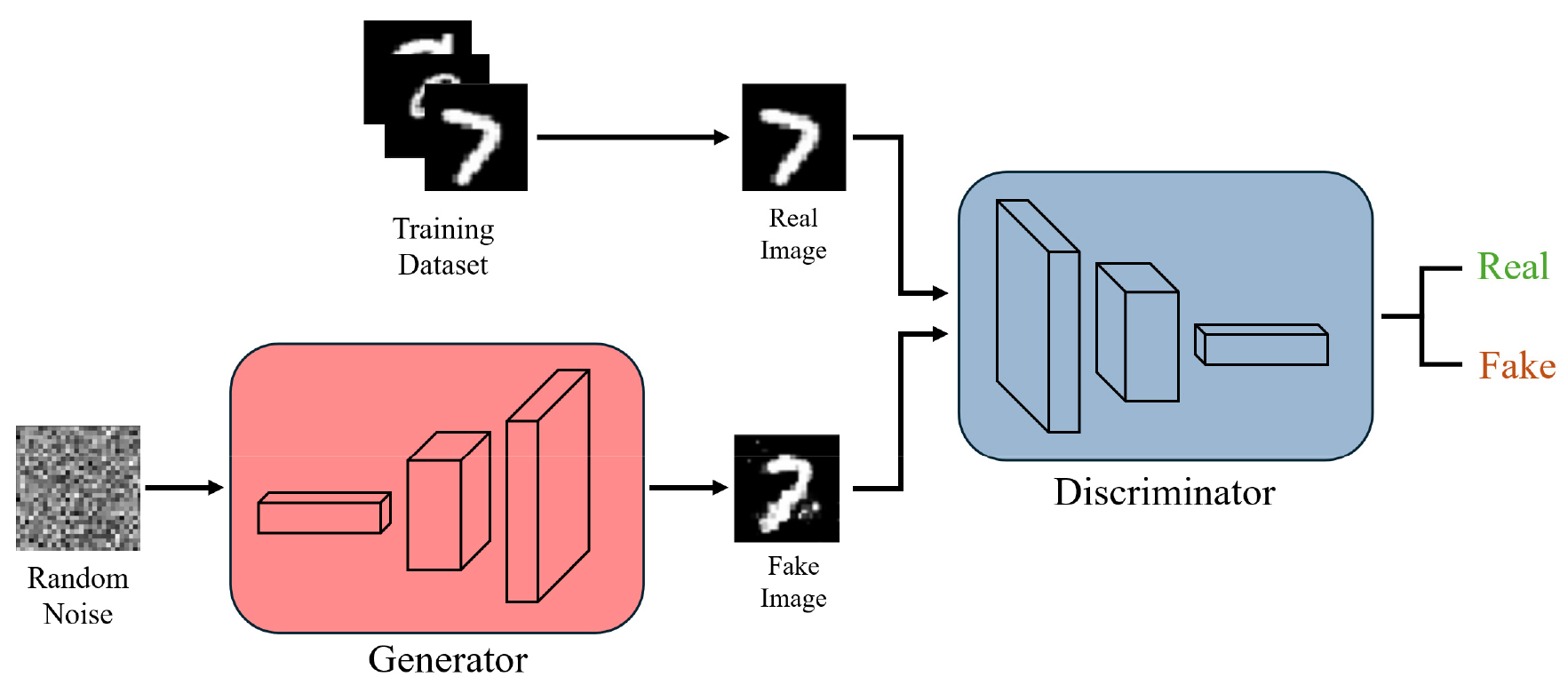
생성자는 잠재 공간(Latent Space)에서 무작위로 추출된 노이즈 벡터(z)를 입력받아 가상의 데이터(G(z))를 생성하며, 판별자를 속이는 것을 목표로 한다. 반면 판별자는 입력된 데이터가 실제 데이터(x)인지 혹은 생성자가 만든 가짜 데이터(G(z))인지를 이진 분류(Binary Classification)하여 정확히 구별하는 것을 목표로 한다. 이 두 네트워크의 경쟁은 Eq. 1의 가치 함수(Value Function) V(G, D)에 대해 생성자는 이를 최소화하고 판별자는 최대화하려는 과정으로 수식화될 수 있으며, 학습이 진행됨에 따라 생성자는 실제와 구분이 불가능할 정도로 정교한 데이터를 생성하는 균형상태에 도달하게 된다.
기존의 GAN은 무작위 노이즈만을 입력으로 사용하기 때문에 생성되는 결과물의 형태나 속성을 사용자가 제어할 수 없다는 결정적인 단점이 있다. 예를 들어, 산불 확산 예측과 같이 특정 발화 지점, 풍향, 지형 조건에 따라 결과가 달라져야 하는 문제에는 일반적인 GAN을 직접 적용하기 어렵다. 이를 해결하기 위해 등장한 CGAN은 생성자와 판별자 모두에게 레이블이나 부가 정보와 같은 조건(y)을 추가로 입력한다(Mirza and Osindero 2014). 이를 통해 모델은 주어진 조건(Condition) 하에서의 데이터 분포를 학습하게 되며 사용자는 입력 조건을 조정하여 원하는 특성을 가진 데이터를 의도적으로 생성할 수 있게 된다. 본 연구에서는 이러한 CGAN의 특성을 활용하여 지형조건 및 시간에 따라 변화하는 기상조건을 입력으로 받아 그에 부합하는 산불 확산 경로를 예측하는 모델을 설계하였다.
3. CGAN 기반 산불 확산 예측 프레임워크
3.1 CGAN 기반 예측 모델 개요
제안된 CGAN 기반 산불 확산 예측모델은 실제 산불 데이터와 기상 및 지형 데이터와 같은 조건부 입력(Conditional Input) 간의 복잡한 비선형 관계를 학습하여 산불 확산을 예측하도록 설계되었다. 이러한 접근법은 앞서 소개한 CGAN의 구조, 즉 생성자와 판별자 모두가 조건부 정보를 입력받아 학습하는 방식을 기반으로 한다. 이를 통해 제안한 산불확산 예측모델은 기온, 습도, 풍속, 풍향과 같은 기상 조건과 경사, 고도, 식생 등의 지형 특성을 각 산불 케이스별 조건으로 입력받아 실제 환경에서 이들 조건이 산불 확산에 미치는 복잡한 영향을 학습할 수 있도록 구성되었다.
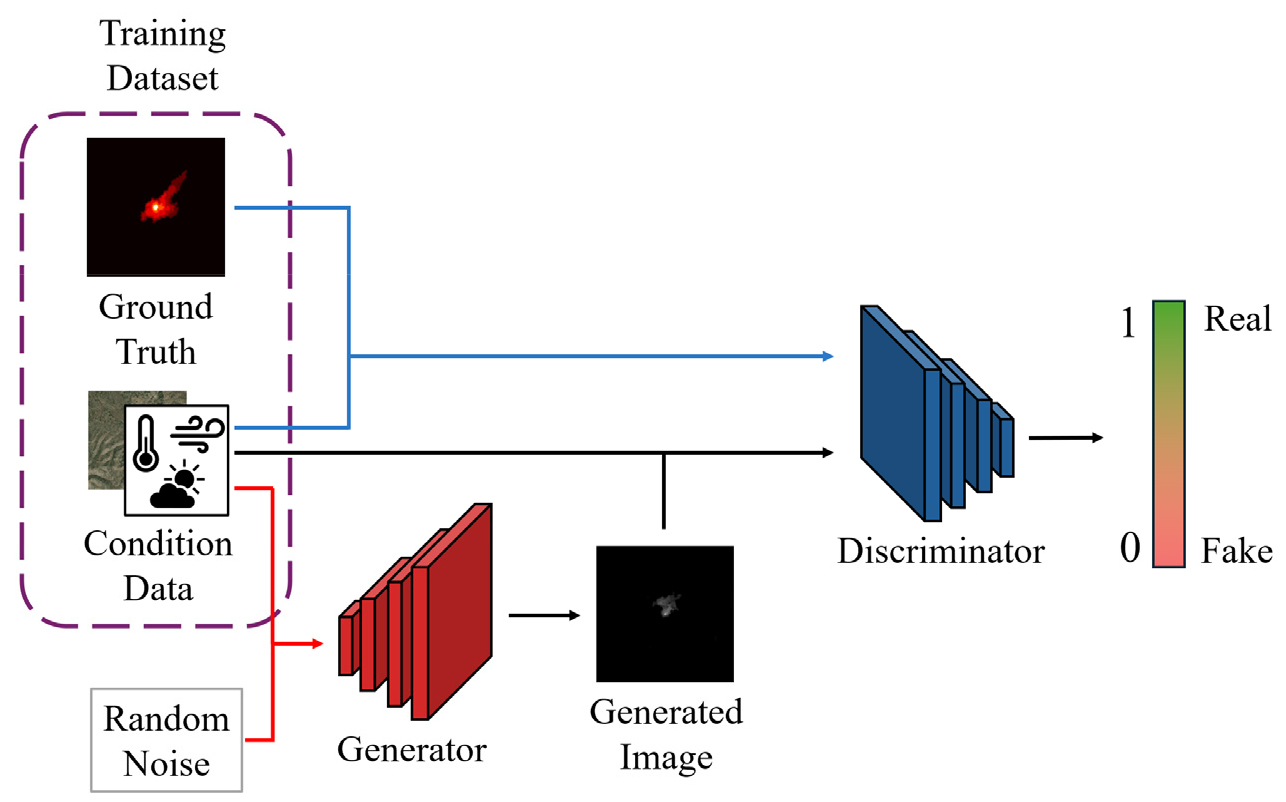
Fig. 3는 본 연구에서 제안한 조건부 생성적 적대 신경망 기반 AI 모델의 전체 구조를 나타낸다. 해당 모델의 학습 시 다음과 같은 데이터가 사용된다: (1) 기상 데이터(128×128×4 형상), (2) 위성지도 지형 이미지(128×128×3 형상), (3) FARSITE 예측 산불확산 이미지(128×128×1 형상), (4) 노이즈 벡터(z, 표준정규분포에서 무작위로 샘플링, 1×128 형상). 생성자는 위 조건부 데이터 중, 노이즈 벡터와 조건부 데이터(위성지도 지형 이미지, 산불 발생 시의 기상 데이터 벡터)를 입력값으로 받는다. 입력된 데이터의 시공간적 정보 특징을 추출한 후 이 정보를 업스케일링(Upscaling) 하여 최종적으로 예측 산불 확산 이미지를 생성하게 된다. 입력 데이터들의 형상은 폭과 높이가 모두 128의 크기로 동일하게 스케일링되었으며 자세한 데이터 스케일링과정에 대해서는 3.2절에서 기술한다.
여기서 생성자의 구체적인 구조는 Fig. 4에 제시한다. 기상 데이터와 위성지도 지형 이미지를 채널 축으로 결합한 데이터(128×128×7 형상)와 노이즈를 입력으로 받아 이를 U-net 기반의 네트워크를 통해 특징을 추출하고 복원하는 과정을 통해 최종적으로 FARSITE 예측 산불확산 이미지와 동일한 차원의 이미지를 출력으로 한다.
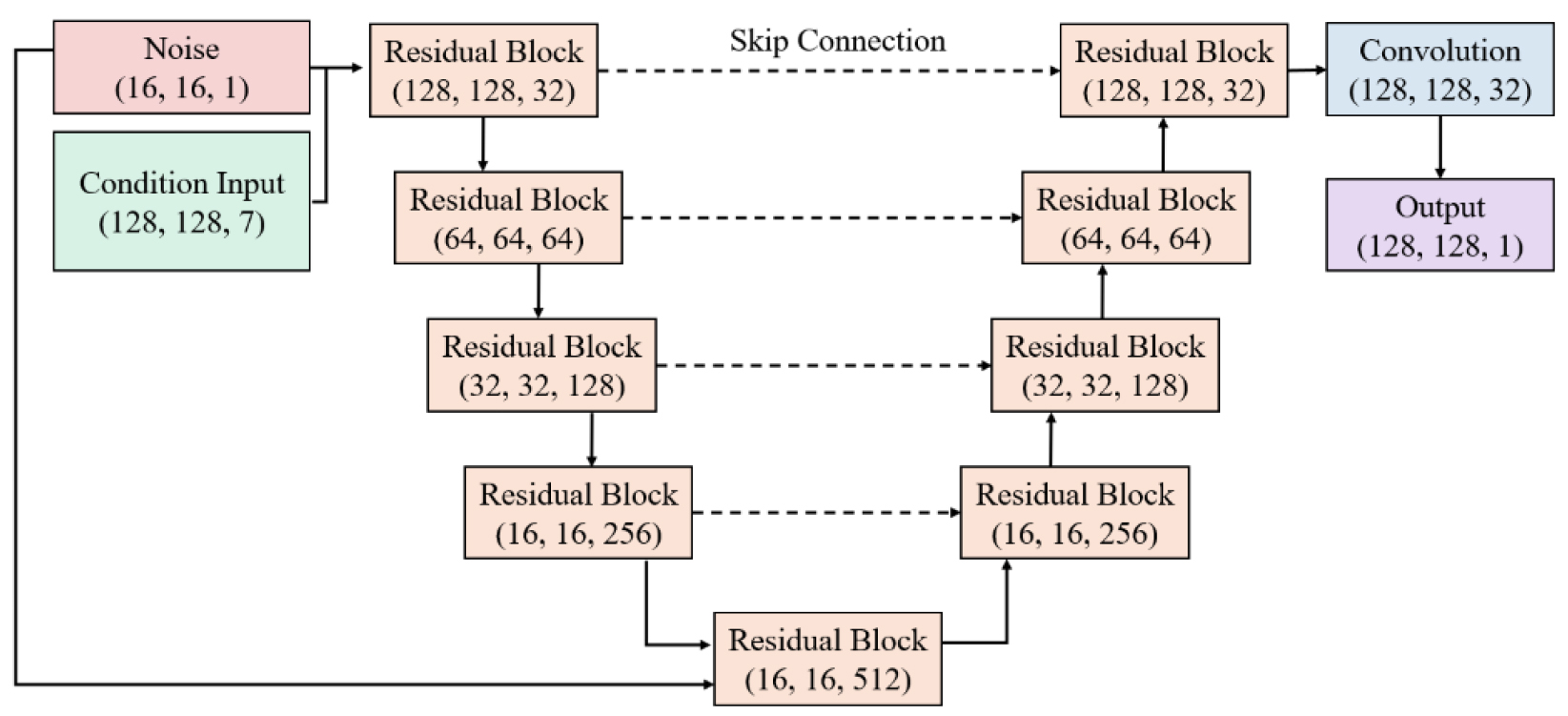
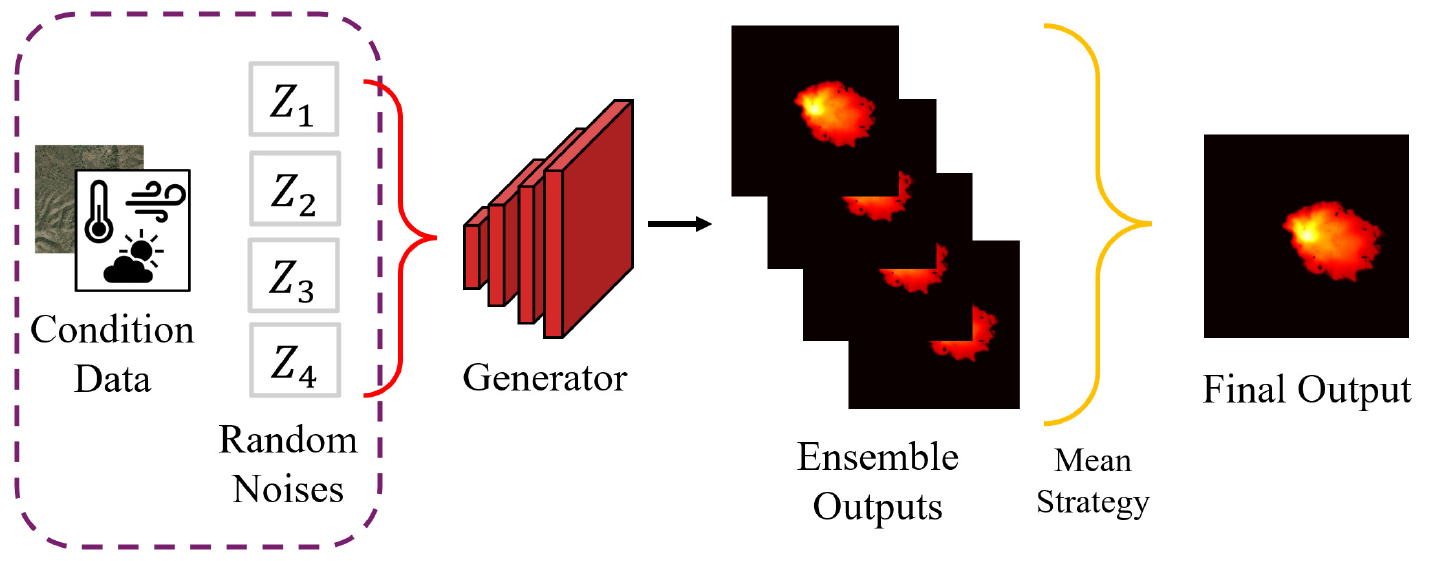
특히, 생성자에 주입되는 노이즈 벡터(z)는 단순히 생성의 다양성을 확보하고 학습의 안정성을 높여주는 역할뿐만 아니라 확률론적 예측(Stochastic Prediction)을 가능하게 하는 핵심 요소로 작용한다(Thedy et al. 2025). 결정론적(Deterministic) 모델이 단일한 입력에 대해 항상 동일한 출력만을 내놓는 것과 달리 제안된 모델은 동일한 지형 및 기상 조건(y) 하에서도 노이즈 벡터 (z)를 무작위로 샘플링함으로써 미세하게 상이한 여러 개의 예측 결과를 생성할 수 있다. 이러한 확률론적 특성은 실제 재난 현장에서 다음과 같은 두 가지 측면에서 의사결정의 유연성과 신뢰성을 제공한다. 우선 Fig. 5와 같이 앙상블(Ensemble) 기법을 적용하여 동일한 조건에 대해 반복적인 예측을 수행하고 이를 평균화함으로써 단일 예측 시 발생할 수 있는 과소예측(Under- estimation) 또는 과대예측(Over-estimation)의 위험을 줄이고, 보다 안정적이고 일반화된 확산 예측 결과를 도출할 수 있다(Wang et al. 2024). 다음으로 최악의 시나리오(Worst-case Scenario) 분석이 가능하다. 현장 지휘관의 판단에 따라 예측된 결과 분포 중 확산 범위가 가장 넓게 예측된 결과를 선택적으로 채택함으로써 인명 피해 방지를 위한 보수적인 방어선 구축 및 선제적 대피 계획 수립이 가능하다. 즉, 제안된 모델은 노이즈 입력을 통해 단순한 예측을 넘어 현장의 상황과 목적에 맞는 다각적인 의사결정을 지원할 수 있다. 본 연구에서는 여러번의 학습과정을 반복하여 하이퍼파라미터 튜닝을 통해 모델이 가장 안정적인 평균 출력값을 도출하는 최소값으로 앙상블 횟수를 N = 5로 설정하였다.
한편 판별자는 생성된 예측 산불 확산 이미지(예측값)와 FARSITE를 통해 얻은 산불 확산 이미지(참값)와 함께 앞서 생성자에 사용한 조건부 데이터를 입력값으로 받는다. 이 세 가지 정보를 결합(128×128×8 형상)하여 각 이미지가 실제인지 혹은 생성된 데이터인지 여부를 판단한다.이 때 판별자는 합성곱신경망을 기반으로 하여 입력 데이터의 폭과 높이는 줄이고 채널을 늘리면서 데이터의 특징을 추출하여 0에서 1 사이의 참일 확률을 출력한다. 이 과정에서 조건부 데이터를 함께 입력함으로써 판별자는 단순히 이미지의 진위를 넘어서 주어진 조건과의 일치 여부까지 고려하여 판단을 내리게 된다.
3.2 학습 데이터 구축 및 전처리
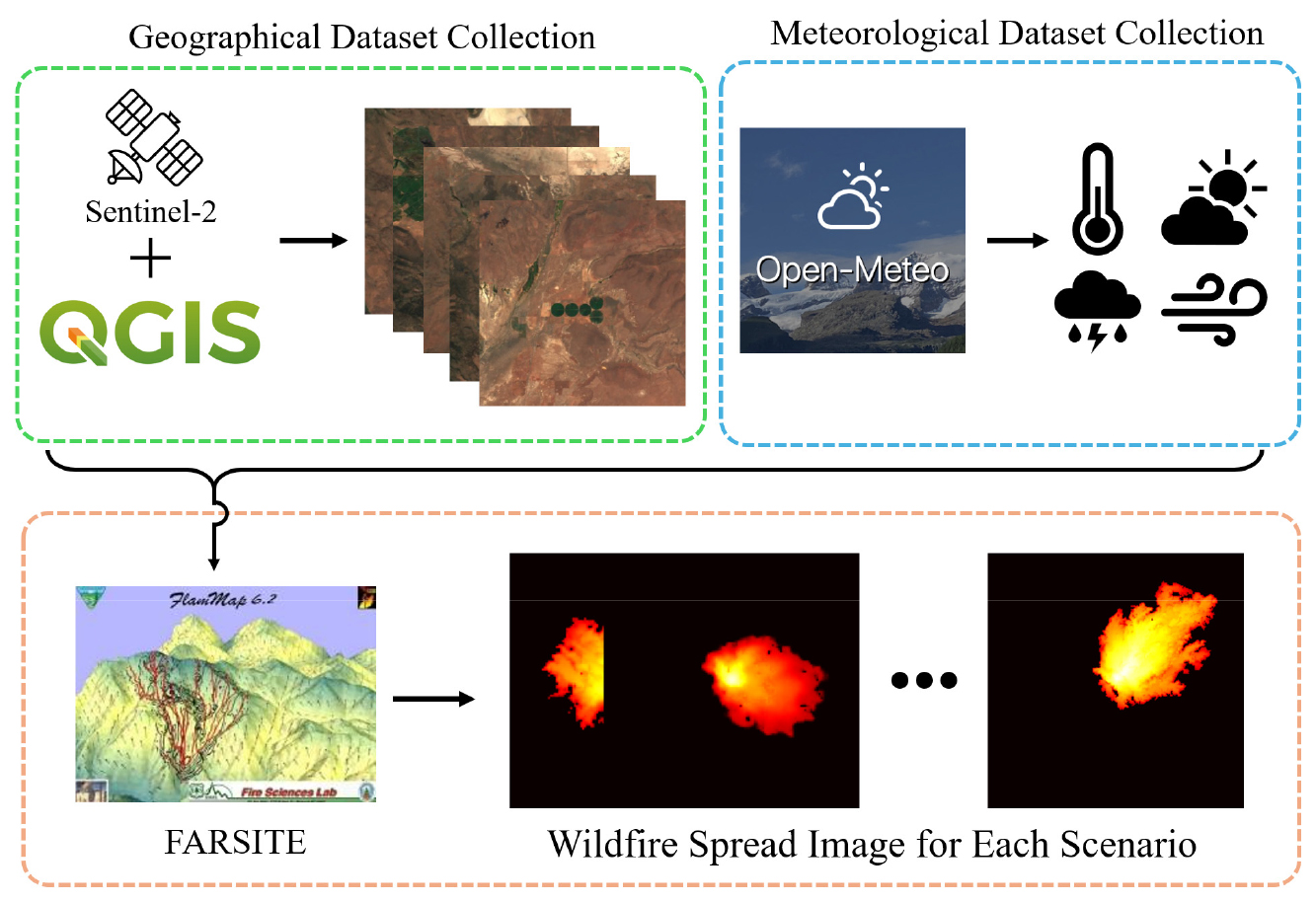
본 연구에서는 제안된 CGAN 모델의 학습을 위해 물리 기반 시뮬레이터인 FARSITE를 활용하여 대규모 산불 확산 데이터셋을 구축하였다. 연구 대상지로는 Fig. 6에 보이는 복잡한 산악 지형과 건조한 기후로 인해 산불 발생 빈도가 높고 관련 연구 데이터가 풍부한 미국 캘리포니아 북부 지역을 선정하였다(Airey-Lauvaux et al. 2022). 추가로 해당 지역은 낮고 마른 풀들이 대부분의 식생을 차지하고 있어 산불확산에 연료가 끼치는 영향이 특정 수준 이상의 일관성을 유지하고 있다고 판단되었다.
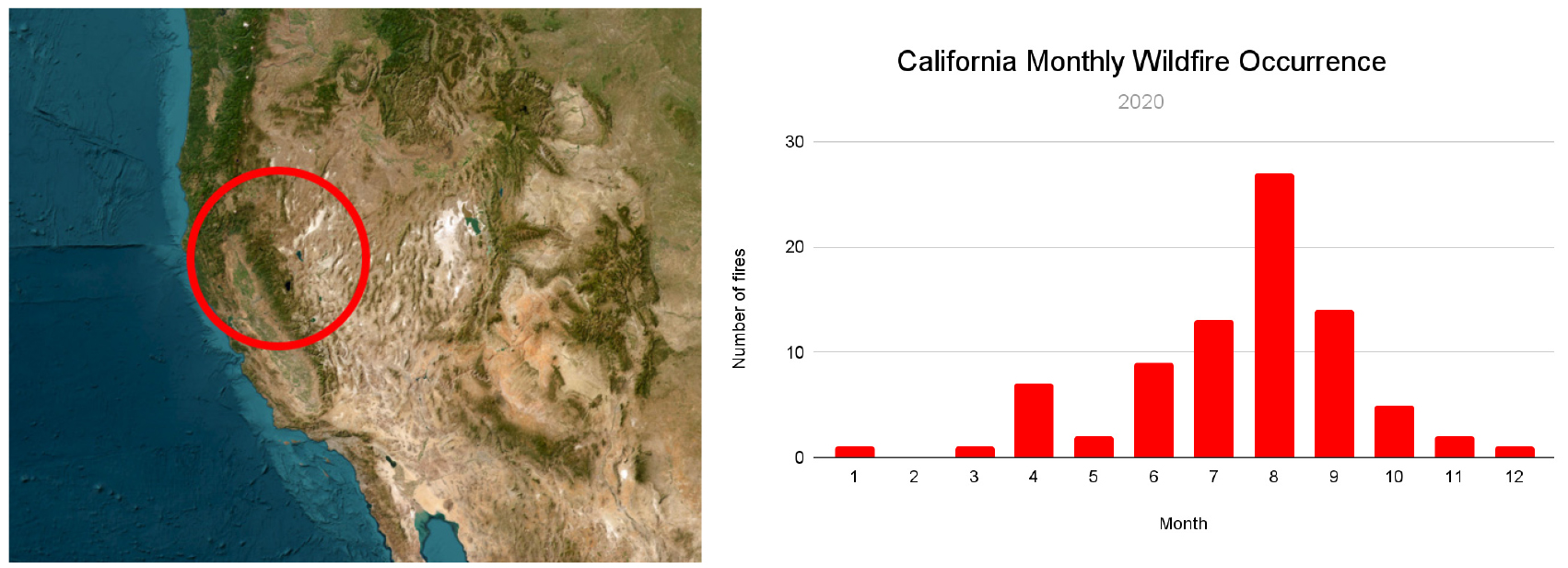
데이터의 현실성을 확보하기 위해 2018-2020년 캘리포니아 산불 기록을 기반으로 산불이 가장 빈번했던 7월부터 9월 사이의 기간을 특정하였다(CAL FIRE 2021). Fig. 7의 프로세스를 따라 해당 지역내에 한 변의 길이가 8 km인 정사각형의 시뮬레이션 대상지를 설정한 뒤 서로 다른 위치의 300개의 발화 지점을 무작위로 선정하고, 각 지점의 좌표값을 이용하여 Open-Meteo API를 통해 수집한 2018-2020년, 7월-9월 동안 70가지의 실제 기상 시나리오를 적용하여 총 21,000건의 시뮬레이션 케이스를 생성하였다. 이때 지형 데이터(위성지도 이미지)는 QGIS를 활용하여 산불 확산 데이터와 동일한 공간해상도로 전처리 후 입력되었다 (Zhu and Woodcock 2014).
학습에 사용될 정답 데이터(Ground Truth)는 시간별 산불 확산 도달시간 영역을 나타낸 이미지로 FARSITE를 이용해서 발화 시점부터 12시간 동안의 산불 확산 과정을 시뮬레이션하여 생성하였다. 해당 데이터는 앞서 설명한 바와 같이 픽셀 당 30 m의 공간해상도를 가지고 있으며 본 연구에서는 단일 채널 이미지 내에 확산의 시간적 정보를 함축하기 위해 산불 도달 시간에 따라 픽셀 값을 차등적으로 매핑하는 방식을 채택하였다. 구체적으로, 발화 시점(0시간)은 픽셀 값 255로, 12시간 경과 시점은 픽셀 값 60으로 선형 변환하여 매핑하였으며 산불이 도달하지 않은 배경 영역은 0으로 설정하였다. 단일 수치로 제공되는 기상 데이터는 128×128 크기의 행렬로 확장(Broadcasting)하여 이미지 형태의 데이터와 차원을 일치시켰고, 구축된 모든 이미지 데이터는 신경망 학습의 안정성과 수렴 속도 향상을 위해 픽셀 값을 [0, 1] 범위로 정규화하여 최종 학습 데이터로 가공하였다.
한편, 생성된 21,000건의 시뮬레이션 중 확산 범위가 설정된 공간 해상도(128×128 pixel)를 초과하여 경계 밖으로 벗어나는 사례는 학습 데이터의 정합성을 위해 제외하였으며, 이에 따라 최종적으로 12,604건의 유효 데이터셋이 구축되었다. 이러한 필터링 과정으로 인해 본 모델은 12시간 이내에 시뮬레이션 영역을 넘어설 정도로 급격하게 확산되는 초대형 산불에 대해서는 예측의 한계를 가질 수 있다. 이는 고정된 입력 해상도에서 오는 구조적 제약으로, 향후 더 넓은 영역을 커버할 수 있는 멀티 스케일 모델링이나 타일링(Tiling) 기법을 적용한 후속 연구를 통해 보완될 필요가 있다
3.3 학습결과
섹션 3.2에서 구축한 총 12,604개의 데이터 중 80 %는 학습용 데이터셋으로 나머지 20 %는 검증용 데이터셋으로 활용하였다. Table 1에는 제안한 CGAN 기반 산불 확산 예측모델의 학습 성능을 평가하기 위해 전체 학습 및 검증 데이터셋에 대해 산출한 평균제곱오차(Mean Squared Error, MSE)를 제시하였다. 또한, 모델의 예측 성능을 보다 직관적으로 확인하기 위해 검증 데이터셋에서 무작위로 선정한 4개의 사례에 대해 예측 결과를 시각화하였다. Fig. 8에는 각 산불 시나리오에 대해 FARSITE로 시뮬레이션한 산불 확산 이미지(좌측 열)와 CGAN 기반 산불확산 예측모델이 예측한 이미지(우측 열)를 나란히 제시하였다. 이미지에서 산불은 중앙 발화지점으로부터 외곽으로 확산되며 색상은 산불의 도달시간을 나타낸다. 노란색에서 빨간색으로 갈수록 해당 지점에 산불이 도달하는 데 소요된 시간이 0시간에서 12시간으로 진행되는 것을 의미하며 검은색 영역은 산불이 도달하지 않은 지역임을 나타낸다. 각 예제별 예측에는 평균적으로 약 0.93초가 소요되었으며 이는 산불 확산 시뮬레이션 1건당 수십 분에서 수 시간 이상 소요되는 FARSITE에 비해 매우 빠른 처리 속도이다.
Table 1.
MSE value of proposed CGAN-based prediction model
| Dataset type | Max Mean Squared Error | Average Mean Squared Error |
| Training | 0.4592 | 0.0229 |
| Test | 0.3646 | 0.0429 |
Fig. 8의 예제 1, 예제 2, 예제 3을 살펴보면 CGAN 기반 산불 확산 예측모델은 시간에 따른 산불 확산 영역을 비교적 정확하게 예측하고 있으며 서로 다른 확산 패턴에 대해서도 효과적으로 대응하고 있음을 확인할 수 있다. 예를 들어, 예제 1과 같이 원형에 가까운 확산 형태뿐만 아니라 예제 2와 같이 특정 방향으로 길게 확산되는 형태도 잘 반영하였다. 또한 도달 시간에 따른 색상 분포 역시 실제 산불 확산 이미지와 유사한 양상을 나타내며 발화 시점에서 시간 경과에 따라 산불이 점진적으로 확산되는 과정을 상대적으로 정확하게 예측한 것으로 나타났다. 반면 예제 4의 경우에는 예측 결과가 실제 산불 확산 형태를 조금 다른 형태의 예측결과를 보여주었는데, 이는 해당 사례의 확산 면적이 상대적으로 작고 다방향으로 복잡하게 확산되는 특이한 양상을 보이기 때문으로 판단된다. 분석 결과 이러한 유형의 산불 확산 사례는 현재 학습 데이터셋 내에 충분히 포함되어 있지 않음을 확인하였다. 향후 예제 4와 유사한 시나리오를 추가적으로 학습 데이터셋에 포함시킨다면 제안된 산불 확산 예측모델의 예측 성능을 더욱 향상시킬 수 있을 것으로 기대된다.

4. 수치예제: 기존 AE기반 산불 확산 예측모델과의 비교
본 연구에서 제안한 CGAN기반 산불 확산 예측모델의 성능을 검증하기 위하여 Jiang et al.(2023)이 개발한 AE 기반 산불 확산 예측모델과의 비교 실험을 수행하였다. 이 모델의 구조는 Fig. 9에 나와 있다. 해당 모델의 핵심 아이디어는 산불 확산의 시간적 변화를 이미지 변환 작업의 형태로 근사하고 여러 종류의 환경 조건 데이터를 이용해 미래의 산불 확산 범위로 매핑하는 것이다. 이를 위해 이 모델은 (1) 각 지형의 고도 데이터를 포함하는 수치표고모델 (DEM)데이터, (2) 가연성 물질의 종류 데이터, (3) 바람, 온도, 습도와 같은 시간에 따라 변하는 기상 변수를 입력받는다. 두 모델 간 공정한 비교를 위해 앞서 섹션 3.2에서 구축한 12,604개의 데이터셋과 동일한 기상조건 데이터를 사용하였고, 지형데이터의 경우에는 본 연구에서 제안하는 모델과 달리 DEM 데이터와 가연성 물질의 종류 데이터를 입력으로 받는다. 이 데이터들은 모두 FARSITE에서 화재 시뮬레이션을 위해 사용되는 입력변수로 해당 데이터를 QGIS로 불러온 뒤 섹션 3.2에서 사용된 발화지점과 동일한 위치에 대해 128×128 사이즈의 이미지로 저장하였다. 추가적으로 해당 모델은 초기 산불 확산 정보(예: 발화 3시간 후의 확산 영역)를 입력 변수로 포함하고 있다. 이는 어느정도 정답을 제공하는 것이기 때문에 모델 성능 향상에는 도움이 될 수 있으나 초기 확산 정보를 사전에 알고 있어야 한다는 점에서 실시간 또는 조기 예측이라는 실제 적용 목적에는 부합하지 않는 측면이 있다. 따라서 본 비교 실험에서는 해당 입력 변수를 제외한 형태로 Fig. 9와 같이 AE 기반 산불 확산 예측 모델을 재구성하여 공정한 비교가 이루어지도록 하였다.
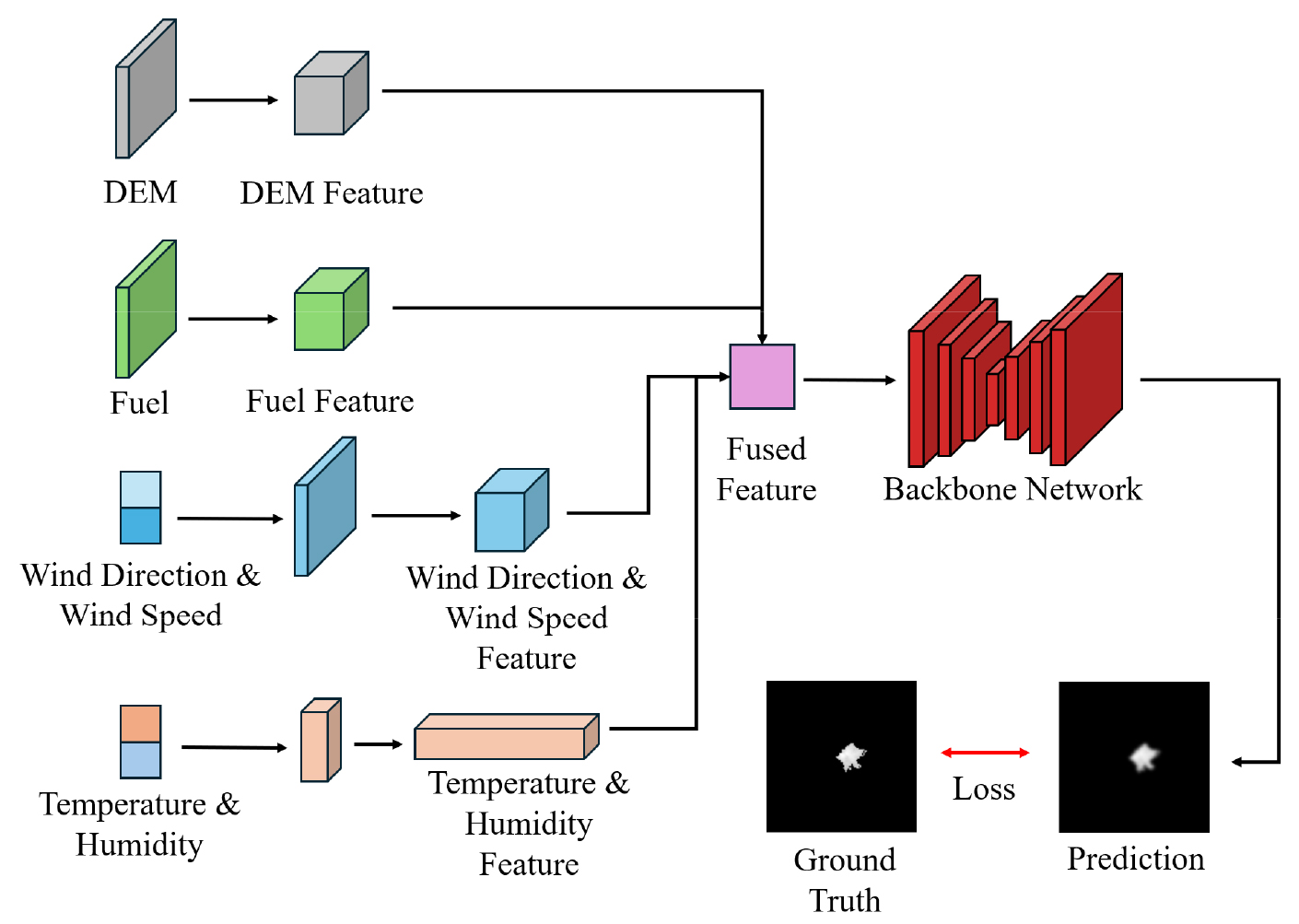
Table 2의 결과를 보면 MSE 평균값이 학습 데이터셋, 검증 데이터셋 모두에서 CGAN 기반 예측모델의 결과보다 높게 나오는 것을 확인할 수 있다. 이는 픽셀당 오차로 보더라도 CGAN 기반 예측모델의 예측성능이 더 뛰어남을 알 수 있다. 다만 MSE 최대값은 AE기반 예측 모델의 결과가 CGAN 기반 예측모델의 결과와 비슷하거나 낮은 모습을 보이는데 이는 산불 확산 이미지 데이터의 특성 때문으로 분석된다. 현재 만들어진 산불 확산 이미지 데이터는 발화 직후에서 12시간 후까지 산불이 번진 영역에 255에서 60 사이의의 픽셀값을 대응시켰고 산불이 번지지 않은 구역은 0의 픽셀값을 갖는다. 이때 산불이 크게 번지지 않은 시나리오라면 이미지에서 대부분의 픽셀이 0값을 가지고 소수의 픽셀만 산불 확산에 의한 값을 가지는 편향된 데이터 특성을 갖기에 픽셀 당 오차를 줄이는 AE기반 에측모델의 오차가 작은 것으로 해석된다.
Table 2.
MSE value of AE-based prediction model
| Dataset type | Max Mean Squared Error | Average Mean Squared Error |
| Training | 0.4066 | 0.041 |
| Test | 0.4132 | 0.05983 |
위에서 설명한 평가지표의 문제점을 해결하고 산불의 경계면에 대한 고차원의 복잡한 표현을 잘 예측하는지 성능을 비교하기 위해 본 연구에서는 경계선 평균 절대 오차(Boundary mean absolute erorr, BMAE)를 평가 지표로 제안한다. BMAE는 실제 화재 이미지와 예측 화재 이미지 각각에서 라플라시안 필터를 통해 경계면을 추출하고 두 경계면 영역의 합집합을 생성하여 계산한다. 합집합 마스크를 사용하는 이유는 실제로는 화재가 발생했으나 예측하지 못한 영역과 화재가 없는데 있다고 예측한 영역의 경계 오차를 모두 포함하여 평가하기 위함이다.
Table 3과 Table 4의 값을 비교하면 두 모델의 MSE 값을 비교하였을때보다 큰 차이로 AE 기반 모델의 성능이 CGAN기반 모델보다 떨어짐을 확인할 수 있다. 이는 앞서 설명한 바와 같이 AE 기반 모델이 확산 경계를 흐릿하게 예측하여 경계 영역의 픽셀값 오차가 누적된 반면 CGAN 기반 모델은 적대적 학습을 통해 화재의 경계면을 보다 명확하게 생성함으로써 실제 화재 전선과의 오차를 최소화했음을 시사한다.
Table 3.
BMAE value of proposed CGAN-based prediction model
| Dataset type | Max Mean Squared Error | Average Mean Squared Error |
| Training | 0.1699 | 0.1291 |
| Test | 0.2777 | 0.1975 |
Table 4.
BMAE value of AE-based prediction model
| Dataset type | Max Mean Squared Error | Average Mean Squared Error |
| Training | 0.4701 | 0.2211 |
| Test | 0.5696 | 0.2629 |
AE기반 산불 확산 예측모델의 성능을 정성적으로 평가하기 위해 Fig. 8과 마찬가지로 Fig. 10의 좌측 열에는 실제 산불 확산 이미지를 우측 열에는 AE기반 산불 확산 예측모델의 예측 이미지를 배치하였다. 예제 2와 예제 4의 경우, 산불 확산의 방향성과 대략적인 범위는 일정 부분 유사하게 예측된 것으로 보인다. 그러나 확산 영역의 테두리 등 세부적인 경계 표현은 뚜렷하지 않고 흐릿하게 나타나는 경향이 있으며, 이는 예측 결과의 해상도가 떨어진다는 점을 시사한다. 또한 산불의 도달 시간을 표현하는 색상 분포 역시 본 연구에서 제안한 딥러닝 기반 예측 모델보다 정확도가 낮은 것으로 확인되었다. 예제 1은 시각적으로 확인했을 때 비슷해 보이긴 하나 전체적인 확산영역 예측 자체를 과소예측하는 문제가 발생했다. 예제 3의 경우엔 위쪽으로 번지는 산불을 아예 예측하지 못 하였다. 이와 같은 예측 실패는 실제 산불 상황에서 AE기반 산불 확산 예측모델을 활용할 경우 아무리 빠르고 효율적인 예측이 가능하더라도 의사결정에 활용될 수 없는 심각한 한계를 지닌다는 점에서 매우 치명적인 문제라고 할 수 있다.

5. 결 론
본 연구에서는 기존 물리 기반 시뮬레이터의 연산 효율성 한계와 전통적인 딥러닝 모델의 정확도 문제를 동시에 해결하기 위해 조건부 생성적 적대 신경망(CGAN) 기반의 확률론적 산불 확산 예측모델을 제안하였다. FARSITE 시뮬레이터를 통해 구축된 대규모 데이터셋을 기반으로 학습된 본 모델은 실험을 통해 다음과 같은 실무적 가치와 학술적 의의를 입증하였다.
첫째, 골든타임 확보를 위한 신속한 예측 성능의 구현이다. 제안된 모델은 물리 기반 모델인 FARSITE와 대등한 수준의 예측 정확도를 유지하면서도 연산 속도는 비약적으로 향상되었다. 이러한 신속한 예측 성능은 산불 발생 초기 단계에서 산불 진압과 대응을 위한 의사결정을 지원하는 데 있어 핵심적인 역할을 수행할 수 있다.
둘째, 적대적 학습을 통한 예측 화선의 구조적 정밀도 향상이다. 비교 실험 결과, 기존의 오토인코더 기반 모델은 픽셀 단위 손실 함수에 의존함으로써 화재 확산 패턴이 과도하게 평활화 되거나 흐릿해지는 경향을 보였다. 반면 본 연구의 CGAN 기반 프레임워크는 더욱 선명하고 구조적으로 충실한 화재 경계면을 생성함으로써 확산 단계별로 보다 실효성 있는 대응 전략 수립에 기여할 수 있음을 확인하였다.
다만, 본 모델은 고정된 도메인 크기 내에서 시뮬레이션 데이터만을 기반으로 학습되었다는 점에서 초대형 산불이나 매우 불규칙한 실제 산불 이벤트에 대한 일반화 성능에는 일정한 한계가 존재한다. 향후 연구에서는 이러한 한계를 극복하고 실전 배치가 가능한 수준으로 모델을 고도화하기 위해 다음과 같은 연구 방향을 제안한다.
1) 실측 데이터 통합 및 도메인 적응: 본 연구는 Ground truth로 FARSITE의 시뮬레이션 데이터에 의존하고 있기 때문에 FARSITE의 산불 예측 정확도에 따라 모델의 실제 산불에 대한 예측 정확도가 의존하게 된다. 따라서 본 연구에서 제안한 CGAN 기반 산불 확산 예측 모델의 실제 산불에 대한 예측 성능을 높이려면 FARSITE의 시뮬레이션 데이터와 실제 산불 관측 데이터(위성 및 항공 영상) 간의 분포 차이를 줄여야한다. 이를 해결하기 위해 도메인 적응(Domain Adaptation)이나 전이 학습(Transfer Learning) 기법을 도입해야 한다. 이를 통해 가상 환경에서 학습된 모델이 실제 재난 현장에서도 강건하게 작동하도록 개선할 필요가 있다.
2) 물리 정보 기반 신경망(Physics-informed ML) 도입: 딥러닝 모델의 블랙박스(Black-box) 특성을 완화하기 위해 에너지 보존 법칙이나 연료 소비 메커니즘과 같은 물리적 제약 조건을 학습 과정에 통합하는 연구가 필요하다. 이는 모델이 단순히 데이터 패턴만을 모사하는 것을 넘어 물리적으로 타당한 예측 결과를 도출하도록 유도할 것이다.
3) 예측 시공간 확장: 현재의 단기 예측을 넘어 24시간 이상의 장기 예측이 가능하도록 모델의 시계열 처리 능력을 강화하고 다양한 식생 및 연료 조건을 학습 데이터에 포함함으로써 모델의 범용성을 확보해야 한다.
