

1. 서 론
2. PCA 기반 이상탐지 기법
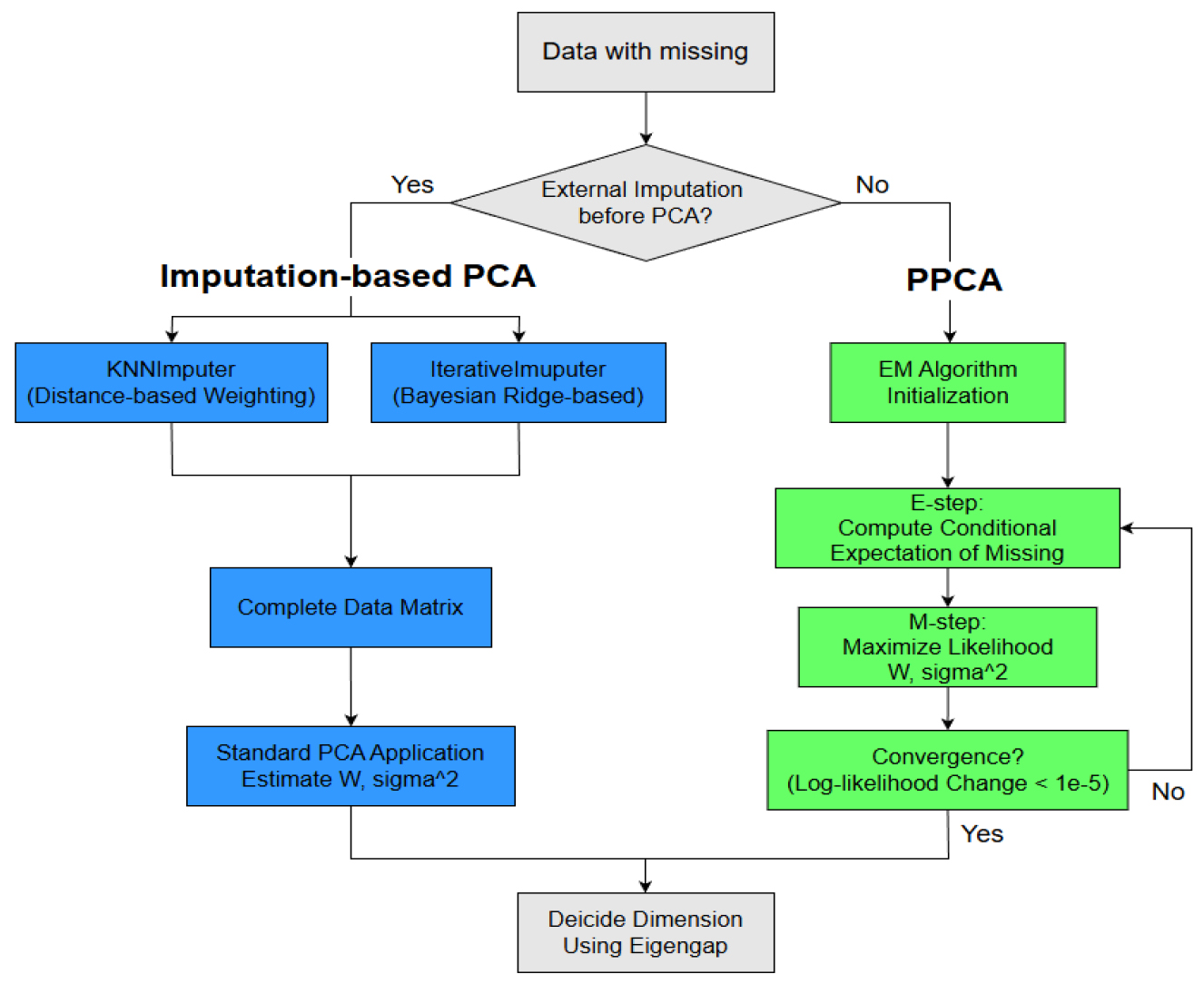
2.1 결측값 대치 기반 PCA (Imputation-based PCA)
2.2 확률적 PCA (Probabilistic PCA, PPCA)
2.3 이상탐지 성능 평가 기준 (SPE)
3. 수치적 검증 실험 설계
3.1 데이터 생성 및 손상 시나리오
3.2 이상탐지 지표(SPE) 및 통계적 임계값 설정
3.3 성능 평가를 위한 실험 설계
4. 수치적 검증 결과
4.1 이상상태 탐지 성능 평가
4.2 연산 복잡도 평가
4. 결 론
1. 서 론
진동 기반 구조물 건전성 모니터링(SHM)은 가속도계로 측정된 진동 신호로부터 구조물의 동적 모드(mode)를 식별하고, 이를 토대로 구조물의 이상상태 발생 여부를 평가하는 기술이다(Doebling et al. 1996). 특히 토목 구조물은 인위적인 가진(excitation)이 어렵고 교통 하중의 영향이 상존한다. 따라서 주로 공용 중에 계측되는 상시 진동을 통해 동적 모드를 추정한다. 이러한 상시 진동은 구조물에 가해지는 하중 특성에 따라 특정 시간대에는 일부 동적 모드를 충분히 가진시키지 못할 수 있다. 이에 해당 모드 정보는 Fig. 1과 같이 장기 계측 데이터베이스(Database, DB)에 결측치(missing values)처럼 표현된다. 이러한 결측치의 존재는 이상탐지 알고리즘의 적용을 불가능하게 만드는 주요 한계점으로 작용한다. 간단한 결측치 처리 방법은 결측치가 포함된 시점의 데이터를 단순 삭제하고, 모든 모드가 식별된 시간대의 데이터만을 선별하여 분석에 사용하는 것이 일반적이다.
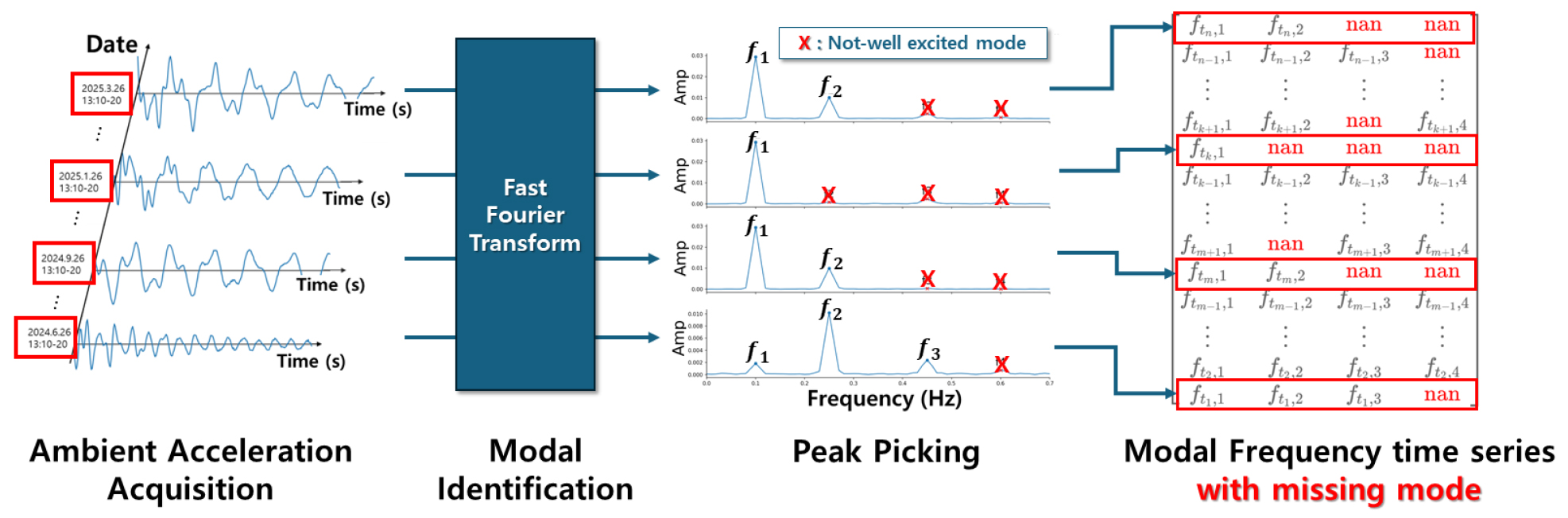
하지만 이러한 전처리 방식은 해당 시간대의 구조물 상태 정보를 활용하지 못하게 만들어 이상탐지 성능 저하 및 탐지 지연으로 이어질 수 있다. 따라서 신뢰성 있는 이상탐지 성능을 확보하기 위해서는 계측 데이터의 결측치를 효과적으로 처리할 수 있는 방법론이 실무에서는 필수적으로 요구된다.
최근 진동 기반 SHM 분야에서 데이터 결측 문제를 해결하기 위해 다양한 접근법이 시도되고 있다. 가장 간단한 방법으로 평균 혹은 중앙값 대치법과 같은 단순 통계 기법이 사용되었으나, 이는 데이터의 고유한 상관성을 왜곡한다는 한계가 있다. 이를 극복하기 위해 최근 연구들은 KNN(K-Nearest Neighbors), MICE(Multiple Imputation by Chained Equations)와 같은 다변량 통계 기법부터 GAN(Generative Adversarial Networks)이나 LSTM(Long Short-term Memory)과 같은 딥러닝 모델을 활용한 보간 기법들이 제안되고 있다(Cho et al. 2020; Lei and Sun 2020; Zhang 2019). 하지만 실제 현장에서 운용되는 SHM 시스템은 장기 계측을 통해 새로운 데이터가 지속적으로 유입되는 환경에 놓여 있다. 이러한 온라인 모니터링 환경에서는 구조물의 현재 상태를 정확히 반영하기 위해 모델의 재학습과 새로운 데이터에 대한 이상 유/무 판단은 필수적이다. 이러한 측면에서 알고리즘의 연산 비용이 과도하게 높다면 데이터가 누적될수록 이를 재학습하는 시간 및 자원을 현장에서 수용하기 어렵다. 이에 실무적인 시스템 운용에 큰 걸림돌로 작용한다. 따라서 실제 현장에 적용되는 이상탐지 기술은 탐지의 정확도뿐만 아니라, 계산 효율성이 통합적으로 고려되어야 한다.
이에 본 연구에서는 결측치가 포함된 실제 환경에서 이상탐지 알고리즘의 실무적 적용성(정확도 및 계산 효율성)을 향상시키기 위한 방법론을 도출하고자 한다. 이를 위해 결측치를 사전에 채워 넣는 결측값 대치 기반 PCA(Imputation-based PCA) 접근법과 결측 처리가 알고리즘 내에 내재된 PCA 접근법을 비교 분석하였다. 본 연구는 다양한 결측 시나리오에서 두 접근법의 이상탐지 정확도(오경보율 및 탐지율)뿐만 아니라, 온라인 SHM 시스템 적용의 핵심 지표인 계산 효율성을 정량적으로 평가함으로써 실제 현장 적용에 가장 적합한 실용적 대안을 제시하고자 한다.
2. PCA 기반 이상탐지 기법
진동 기반 구조물 이상탐지 방법은 정상 상태(Normal condition)에서 계측된 고유진동수와 같은 동적 특성을 손상 지표(Damage Indicator)로 활용한다. 정상 상태의 데이터들을 이용하여 정상상태의 패턴을 표현하는 기저 모델(Baseline Model)을 구축하고, 새롭게 계측된 손상 지표를 기저 모델과 비교하여 이상상태를 판단한다. 그러나 고유진동수와 같은 손상 지표는 구조적 손상뿐만 아니라 온도와 같은 외부 환경 조건에 의해서도 민감하게 변동한다. 주성분 분석(Principal Component Analysis, PCA)은 이처럼 정상 상태 데이터에 내재된 복잡한 환경적 변동성을 효과적으로 모델링하는 기법으로 널리 활용되었다(Yan et al. 2005; Jin et al. 2015). 하지만 일반적인 PCA 알고리즘은 데이터에 결측치가 존재할 경우 연산이 불가능하다는 명확한 한계가 있다. 서론에서 언급했듯이 실제 환경에서는 가진 조건에 따라 모드가 누락되는 경우가 빈번하므로 이는 PCA 기반 이상탐지 기법의 실무 적용을 가로막는 주요 걸림돌이 된다. 이러한 문제점을 해결하기 위한 접근법은 크게 두 가지로 분류할 수 있다.
1) 결측치 대치(Imputation) 후 PCA 적용: KNN, MICE 등 통계적 기법으로 결측치를 먼저 채운 뒤, 완성된 데이터셋에 표준 PCA를 적용하는 방식
2) 결측치 추정을 포함하는 PCA 적용: 확률적 PCA(PPCA)와 같이 알고리즘 자체에 결측치를 추정하는 메커니즘이 내재된 방식
2.1 결측값 대치 기반 PCA (Imputation-based PCA)
결측치를 사전에 대치(imputation)한 후 표준 PCA를 적용하는 방식으로 다양한 방법들이 존재한다. SHM의 고유진동수 데이터는 비정형적이고 비균일한 결측 패턴을 보이는 경우가 많아, 평균이나 중앙값 같은 단순 대치법을 사용할 경우 변수 간의 본래 상관 구조가 왜곡될 수 있다. 이에 이러한 왜곡을 최소화하고 더 정교하게 결측치를 추정하기 위해, 본 연구에서는 다음 두 가지 기법을 적용하였다.
∙ KNN (K-Nearest Neighbors) 대치: 이 방법은 표준화된 특성 공간에서 유클리드 거리를 기준으로 가장 가까운 k=5 개의 이웃 샘플(행)을 찾고, 이 이웃들의 관측값을 (거리 역수) 가중 평균하여 결측치를 추정(scikit-learn의 KNNImputer (Pedregosa et al. 2011)를 활용)한다. 본 연구에서 k=5(weights=’distance’)를 선택한 이유는 소수의 이웃 데이터에만 의존할 때 발생할 수 있는 과적합을 방지하고 거리 기반 가중치를 통해 데이터의 국소적 패턴을 안정적으로 반영하여 추정의 강건성을 확보하기 위함이다.
∙ MICE (Multiple Imputation by Chained Equations) 대치: 이 방법은 각 변수를 나머지 모든 변수에 대한 조건부 회귀 모델로 간주하여 순차적으로 갱신하며, 이 과정을 수렴할 때까지 반복한다. 본 연구에서는 Bayesian Ridge 회귀 모델을 기반으로 10회 반복하여 단일 완전 데이터를 생성하였다(scikit-learn의 IterativeImputer (Pedregosa et al. 2011)를 사용). 이때 max_iter=10은 반복 회귀의 수렴을 보장하면서 계산 효율성을 확보하기 위한 기본값으로 선택하였고, BayesianRidge()를 예측기로 사용한 이유는 다변량 관계를 안정적으로 모델링하기 위함이다.
결측치가 보완된 완전한 데이터셋에 표준 PCA를 적용하여 주성분 공간으로 변환하였다. 주성분의 수는 고유치들을 내림차순으로 정렬한 뒤, 인접 고유치 간의 차이(1차 차분)가 급격히 커지는 지점을 선택하는 eigengap 기법을 통해 결정하였다(Jin and Jung 2018). eigengap은 고유치 차이를 기반으로 최적 차원을 자동 선택하여 특정한 임계치를 사전에 지정할 필요가 없다는 장점을 가진다. 본 연구에서 사용된 결측값 대치 알고리즘은 오직 훈련 데이터(training data)에만 적합(fit)시킨 후, 이 모델을 검증 및 시험 데이터에 동일하게 변환(transform) 적용하여 데이터 누수(data leakage)를 엄격히 방지하였다.
Table 1.
Hyperparameters for imputation methods
| Method | Hyper parameter | Value/setting |
| KNN | n_neighbors | 5 (weights=‘distance’) |
| MICE | max_iter | 10 |
| MICE | estimator | BayesianRidge() |
| All Methods | Latent Dimension Selection | eigengap alogrithm |
2.2 확률적 PCA (Probabilistic PCA, PPCA)
앞서 2.1절에서 설명한 대치(imputation) 기반 접근법과 달리, 확률적 PCA(PPCA)는 결측치 추정 메커니즘이 알고리즘 내에 통합된 생성 모형(generative model)이다(Tipping and Bishop 1999). PPCA는 관측된 고차원 데이터 가, 직접 관측할 수 없는 저차원 잠재 변수(latent variable) (단, )로부터 선형 변환()과 등방성 잡음()을 통해 생성된다고 가정한다(식 (1)~(2)). 따라서 의 확률 분포 는 잠재 변수 를 적분함으로써 얻어지는 주변 분포이며, 이는 평균 와 공분산 행렬 를 가진 가우시안 분포로 모델링된다(식 (3)). 여기서 로, 는 잠재 구조에서 오는 분산을, 는 잡음에서 오는 분산을 반영한다. 이 알고리즘은 표준 PCA가 공분산 행렬의 고유치 분해를 통해 찾는 저차원 주성분 구조를 확률론적 관점에서 재해석한 것이다. 만약 데이터에 결측치가 없다면, PPCA 알고리즘 최대우도(Maximum Likelihood, ML) 추정값은 표본 공분산 행렬 의 고유치 분해(즉,, 여기서 는 고유벡터 행렬, 는 고윳값 대각 행렬)를 통해 해석적 해(analytical solution)로 간단히 구해진다(식 (4)~(5)). 특히 은 의 선택되지 않은 고유치들(부터 까지)의 평균으로 추정되어 노이즈 분산을 나타낸다. 그러나 SHM 데이터와 같이 가진 조건에 따라 결측이 발생한 경우, 관측된 부분만으로 표본 공분산 를 계산하면 이는 편향된(biased) 불완전한 공분산 구조가 된다. 이로 인해 해석 해를 직접 적용할 수 없다.
PPCA는 이 문제를 EM(Expectation-Maximization) 알고리즘을 통해 해결한다. EM 알고리즘의 핵심은, 결측치를 KNN이나 MICE처럼 고정된 값으로 미리 채우는 것이 아니라, 잠재 변수 와 결측된 데이터 성분을 모두 관측되지 않은 가상의 완전한 데이터로 가정하는 것이다. 그 다음, 현재 파라미터(, , )를 기반으로 이들의 기댓값(Expectation)을 계산하고, 이 기댓값을 이용해 다시 파라미터를 갱신(Maximization)하는 과정을 반복적으로 수행하여 PPCA 알고리즘의 파라미터를 최적화한다.
E-step (Expectation-step) 단계에서는 현재 추정된 파라미터(, )와 관측된 데이터(, 여기서 는 샘플 에서 관측된 변수의 인덱스 집합)만을 이용해, M-step에 필요한 충분 통계량(sufficient statistics)들의 기댓값을 계산한다. 구체적으로, 다음 두가지 핵심 값을 계산한다.
∙ 잠재 변수()의 사후 기댓값: (사후 평균) 및 (사후 이차 모멘트) (식 (9), (10)).
∙ 결측치()의 조건부 기댓값: (식 (11)).
이 계산 과정(식 (6), (7), (8), (9), (10))은 계산 편의를 위해 스케일된 정밀도 행렬 (식 (6))을 정의하고, 이를 통해 사후 공분산 (식 (8))과 평균 (식 (9))을 유도하는 과정을 포함한다. 가장 중요한 점은 이 방식이 결측치를 2.1절의 방법론들처럼 고정된 값으로 한 번 대치(imputation)하는 것이 아니라, 매 반복마다 갱신되는 조건부 기대(conditional expectation)로 처리한다는 것이다. M-step (Maximization-step) 단계에서는 E-step에서 계산된 기댓값들(, , 그리고 )을 관측된 완전한 데이터처럼 간주한다. 이 통계량들을 사용하여 로그우도(log-likelihood)를 최대화하는 새로운 파라미터 와 을 갱신한다. 이 E-step과 M-step은 수렴 조건(예: 로그우도 증가량, 파라미터 변화, 최대 반복 수 도달)이 만족될 때까지 반복적으로 수행된다.
본 연구에서는 PPCA의 EM 알고리즘을 직접 구현하였으며, 이를 진동기반 이상상태 탐지에 다음과 같이 모델 설정 및 학습을 고려하여 진행하였다.
∙ 초기화: 계산 효율성을 높이기 위해, 초기화 단계에서는 결측치를 변수별 평균으로 우선 채운 뒤 SVD(Singular Value Decomposition)를 적용함. 이는 표준 PPCA의 관측 변수 공분산 기반 초기화 방식과 유사한 결과를 제공
∙ 데이터 누수 방지: 2.1절의 방법론과 동일하게 모델은 훈련 데이터(training data)에만 적합시켜 데이터 누수(data leakage)를 엄격히 방지함
∙ 수렴 및 과적합 방지: 수렴 조건은 로그우도 증가량의 상대 변화가 0.00001 이하일 때로 설정하여, 계산 효율과 정확성을 동시에 확보하고자 함. 또한 최대 반복 횟수를 100회로 제한하여 과적합을 방지함
∙ 주성분 결정: 훈련 데이터로부터 와 를 추정한 뒤, 주성분의 수는 eigengap 기법을 동일하게 적용하여 결정
2.3 이상탐지 성능 평가 기준 (SPE)
본 연구에서 비교하는 두 접근법(대치 기반 PCA와 확률적 PCA)은 Fig. 2에서 보듯이 결측치 처리 방식에서 근본적인 차이를 가진다. 따라서 두 방법론의 이상탐지 성능을 공정한 기준으로 평가하기 위한 공통 지표가 필요하다. 본 연구에서는 PCA 기반 이상탐지의 표준 지표인 SPE (Squared Prediction Error)를 사용했다. SPE는 모델이 학습한 주성분 공간에서 원본 데이터를 재구성할 때 발생하는 재구성 오차(Reconstruction Error, residual)의 제곱합이다. 훈련(정상) 데이터의 SPE 분포를 통해 통계적 임계값을 설정하고, 새로운 데이터의 SPE가 이 임계값을 초과하면 이상상태로 탐지한다(Fig. 3).
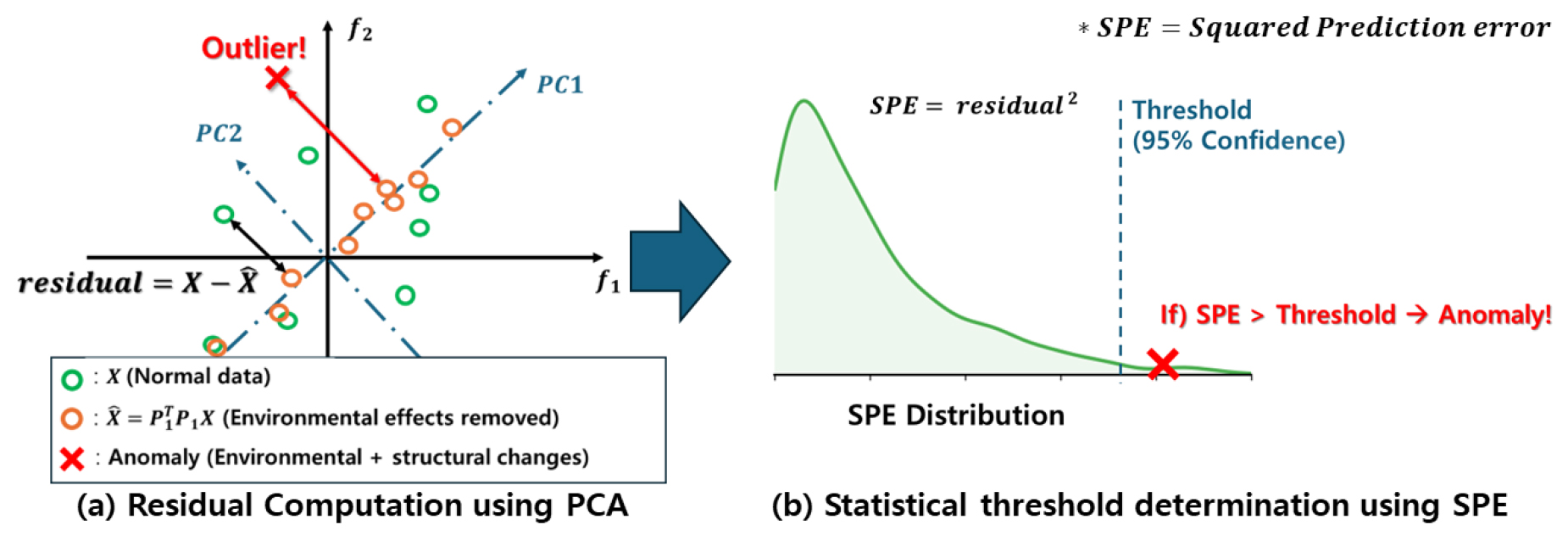
다만, 결측치가 존재하는 데이터 환경에서는 샘플마다 관측된 변수의 개수()가 다르다. 이 경우, SPE는 관측치가 적은 샘플에서 항상 더 작게 계산되는 편향(bias)이 발생하여 공정한 비교가 불가능하다. 따라서 본 연구에서는 각 샘플의 SPE()를 해당 샘플에서 실제 관측된 데이터의 개수()로 정규화(normalization)한 지표를 사용하였다(식 (12)).
정규화된 SPE는 두 접근법에 모두 동일하게 적용하여 보간 성능을 평가하였다.
3. 수치적 검증 실험 설계
3.1 데이터 생성 및 손상 시나리오
제안하는 접근법들의 성능을 검증하기 위해, 실제 구조물의 거동 특성을 모사한 수치 데이터를 생성하였다. SHM에서 PCA 기반 이상탐지의 주요 과제는 환경적 변동성과 구조적 손상을 구분하는 것으로 이를 반영하기 위해 다음과 같은 절차로 데이터를 구성하였다.
1) 환경 변동성 모사: 구조물의 동적 특성에 영향을 미치는 주요 환경 요인으로 온도를 설정하였으며, 실제 서울시의 기온 시계열 데이터(2024.06-2024.09)를 활용하여 외부환경 변화 인자로 구성함(Fig. 4(a))
2) 물성 변화 정의: 온도 변화에 따른 재료의 물성 변화는, 탄성계수(Young’s Modulus, E)와 온도 간의 준선형(Quasi-linear) 관계를 가정함(Fig. 4(b))
3) 유한요소모델(FEM) 구성: 베르누이 빔 이론을 사용하여 단순지지 보로 모델링함. 해당 보는 총 20개의 유한요소로 구성함. 재료 및 기하학적 특성과 FEM 모델에 사용한 변수들은 Table 2에 명시함
4) 고유진동수 데이터 확보: 각 시점의 온도 조건에 해당하는 탄성계수(E)를 유한요소모델의 강성행렬(K) 구성 시 적용한 뒤, 모드 해석을 수행함(Fig. 4(c)). 총 400개의 샘플 데이터(고유진동수)를 생성함
Table 2.
Material properties and finite element model parameters
궁극적으로 이상탐지 알고리즘의 손상 탐지 성능을 평가하고자 데이터 생성 조건(Table 2)에 특정 시점에서의 손상을 부여하는 시나리오를 도출하였다. 본 연구에서는 구조물의 대표적인 두 가지 손상인 점진적 손상과 급격한 손상을 고려하여 데이터를 구성하였으며, 구체적인 손상 시나리오는 다음과 같다(Table 3):
∙ 손상 시나리오 #1(급격한 손상): 전체 400개 데이터 중 320번째 시점에서 중앙부 특정 요소(10-11번째 요소)의 휨 강성의 10% 저하를 모사
∙ 손상 시나리오 #2(점진적 손상): 전체 400개 데이터 중 300번째부터 강성이 선형 감소하여 400번째에서는 특정 요소(10-11번째 요소)의 휨 강성이 10%가 저하되도록 구성
Table 3.
Damage scenarios
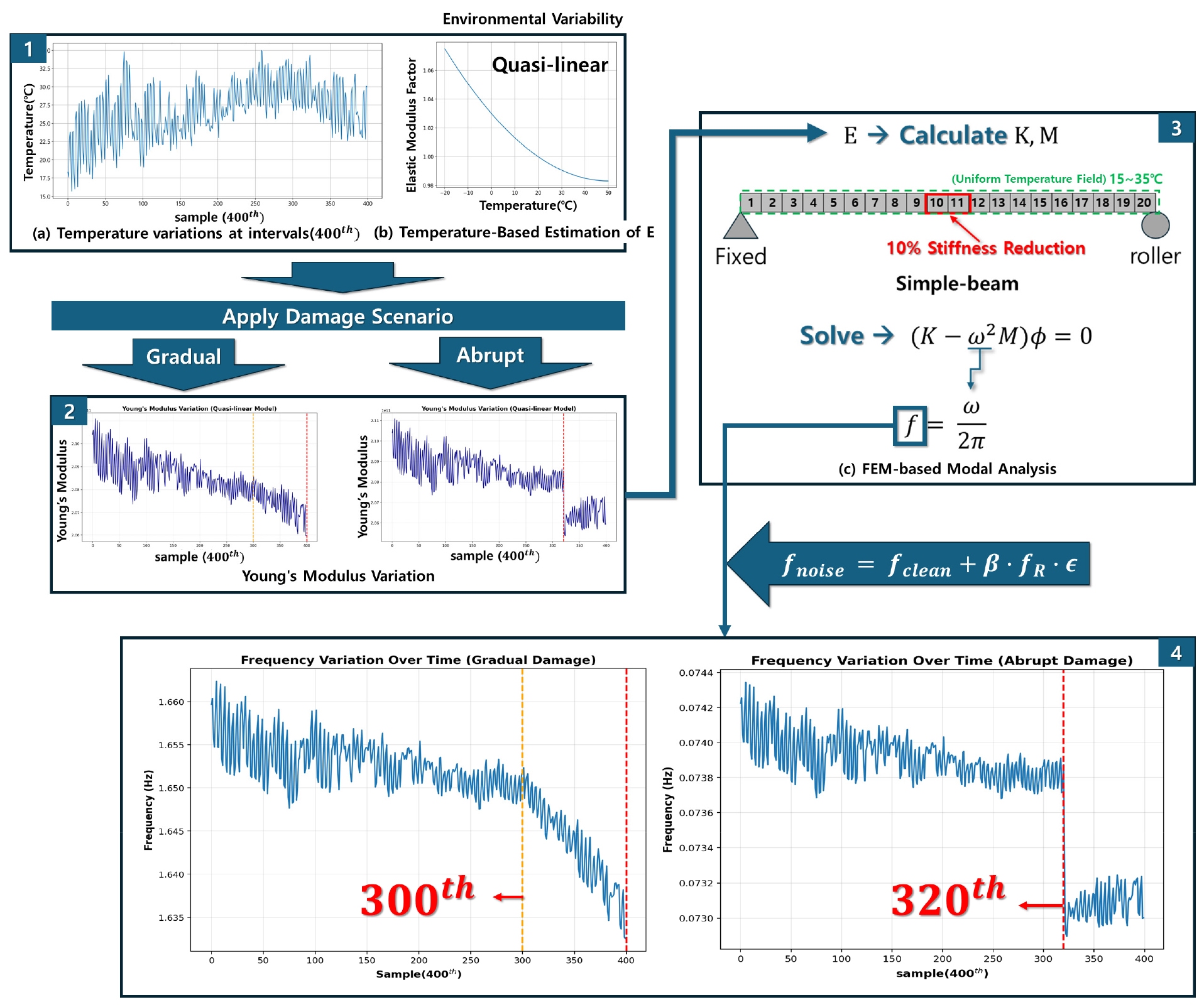
추가적으로 유한요소모델을 통해 얻은 고유진동수 데이터는 이상적인 환경을 가정하고 있으므로, 실제 계측 시스템에서 발생하는 불확실성과 센서 잡음을 반영하기 위해 인위적인 잡음(Noise)을 추가하였다. 잡음은 각 모드별 신호의 RMS(Root Mean Square) 크기에 비례하는 백색 잡음(White noise)를 생성하여 식 (13)과 같이 적용하였다.
여기서 은 FEM 해석을 통해 얻은 고유진동수, 은 해당 모드 신호의 RMS 값이다. 은 평균이 0이고 표준편차가 1인 표준 정규분포 를 따르는 난수이며, 는 잡음 수준을 결정하는 계수이고, 본 연구에서는 는 0.001(60 dB)을 사용하였다.
최종적으로 구성한 고유진동수 시간 이력은 온도 변화에 따른 전역적 변동성(정상 상태), 강성 저하로 인한 국부적 변화(손상 상태)와 계측 잡음을 모두 포함한다. 이렇게 구성된 각 학습 데이터 내 고유진동수들은 스케일 효과(scale effect)를 제거하기 위해 평균 0이고 분산이 1로 정규화(Standardization)하여 각 알고리즘(Imputation-based PCA, PPCA)의 입력으로 사용하였다.
3.2 이상탐지 지표(SPE) 및 통계적 임계값 설정
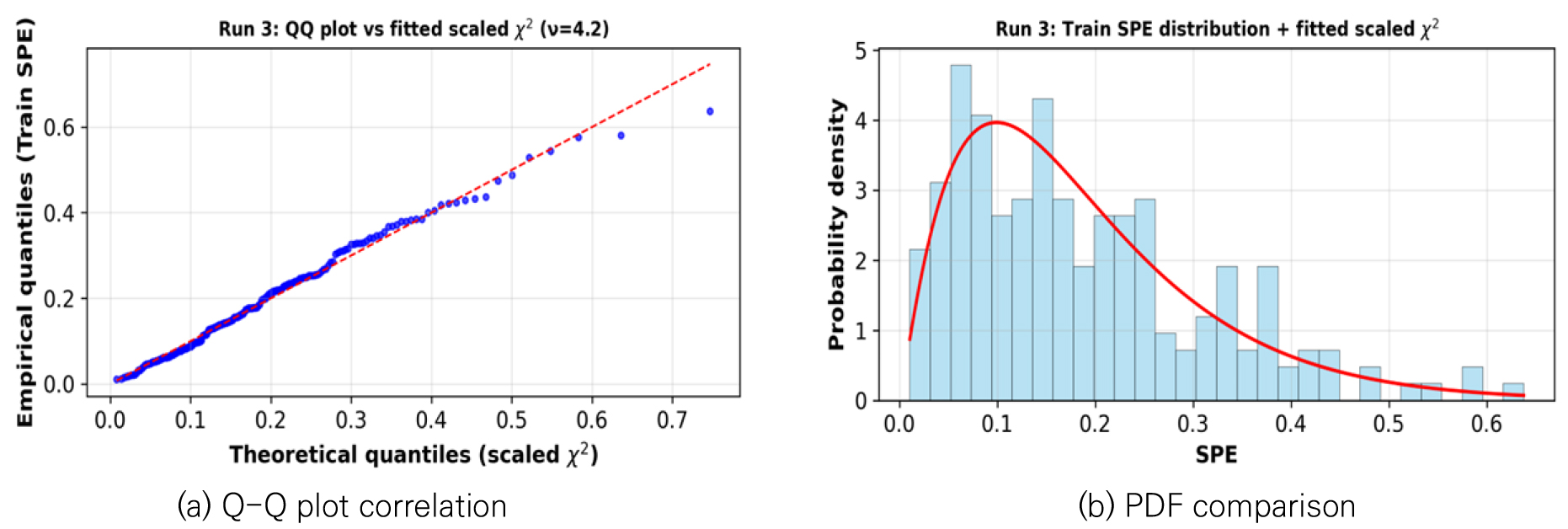
본 연구에서는 PCA 기반 이상탐지 알고리즘의 이상 점수(Anomaly Score)로 SPE(Squared Prediction Error)를 사용하였다. 이상 여부를 판단하는 임계값(threshold)은 학습 데이터(Training data)는 초기 정상 상태 데이터 200개를 모델에 학습시켜 얻은 SPE의 통계적 분포를 기반으로 설정한다. 구체적으로 Jackson & Mudholkar (1979)의 방법에 따라 학습 데이터의 SPE 분포를 스케일된 카이제곱() 분포로 모사할 수 있다. 모사된 카이제곱 분포를 기준으로 95%와 99% 신뢰수준(Confidence Interval)에 해당하는 값을 임계값으로 산정했다(Jackson and Mudholkar 1979). SPE 분포의 적합성은 KS 검정(Kolmogorov-Smirnov test)과 Q-Q plot의 상관계수를 통해 검증하였다. 검증 결과, Fig. 5(a)의 Q-Q plot에서 실제 SPE 데이터가 기준선을 따라 매우 선형적으로 분포하는 것을 확인할 수 있다. 이는 Fig. 5(b)의 확률밀도함수(PDF) 비교와 더불어, 학습 데이터의 SPE 분포가 스케일된 카이제곱 분포를 매우 잘 따르고 있음을 보여준다. 이는 본 연구의 핵심 가정에 대한 중요한 근거가 된다. 즉, 결측치가 존재하는 상황에서 KNN, MICE, PPCA 등의 방법론을 적용하더라도 SPE 분포의 통계적 특성이 왜곡되지 않았으며, 이를 기반으로 설정된 임계값 역시 높은 신뢰도를 가져 이상탐지의 정확성을 보장할 수 있음을 의미한다.
3.3 성능 평가를 위한 실험 설계
3.3.1 평가 구간 및 성능 지표
본 절에서는 2장에서 제시된 세 가지 방법론(KNN, MICE 및 PPCA)의 이상탐지 성능을 정량적으로 비교 평가하였다. 개별 방법론들의 변수들은 2.1절의 Table 1에서 제시된 조건들로 적용하였다. 그리고 최적 주성분 차원 선택은 eigengap 기법으로 모두 동일하게 적용하였다. 성능 검증을 위해 손상으로 인한 급격한 강성 저하 상황을 모사하였으며 총 400개의 샘플들을 생성하였다. 이를 위해 훈련(학습)에 사용되지 않은 데이터를 아래 두 가지 평가 구간으로 나누었다.
∙ 정상 구간 내 오보율 평가: 샘플 201~320번째
∙ 손상 구간 (Damaged) 내 손상 탐지율 평가: 샘플 321~400번째
개별 기법의 이상상태 탐지 성능 평가를 위해 위 두 가지 평가 구간에 대해 다음의 평가 지표를 사용하였다:
∙ 오경보율 (False Alarm Rate, FAR): 정상 구간에서 임계값을 초과한 비율로, 모델의 안정성 평가
∙ 탐지율 (Detection Rate, DR): 손상 구간에서 임계값을 초과한 비율로, 모델의 민감도 평가
3.3.2 실제 조건의 결측치 모사
실제 현장에서 발생하는 결측 모드를 모사하기 위해 결측률(Missing Rate)과 결측 발생 메커니즘(Missing method)를 토대로 두 가지 검증 실험을 설계하였다.
1) 무작위 결측 생성 메커니즘(Missing Completely at Random, MCAR)에 따른 결측률 민감도 분석
첫 번째 검증 실험은 데이터의 결측이 특정 모드나 시간과 무관하게 데이터셋 전체에 걸쳐 산발적으로 발생하는 상황을 가정한다. 이는 무선 센서 네트워크의 일시적인 통신 장애, 환경적 노이즈로 인한 결측 뿐만 아니라 센서 자체의 오작동 등 예측 불가능한 요인에 의해 발생하는 결측을 대표한다. 이러한 유형의 결측은 특정 저주파수 모드처럼 일반적으로 안정적인 신호에서도 발생할 수 있는 문제 상황을 모사한다.
∙ 결측 데이터의 비율이 성능에 미치는 영향을 분석함. 전체 데이터 행렬(샘플 수 x 모드 수, 400 x 6)을 구성하는 총 셀의 개수를 기준 결측률만큼의 행렬 요소를 무작위로 선택하여 해당 고유진동수를 nan 값으로 표시하여 결측을 모사함. 이는 MCAR (Missing Completely at Random) 방식을 기준으로 결측률을 각각 10%, 20%, 30%로 변화시키며 FAR과 DR을 측정하여 각 기법들의 성능을 비교함
2) 특정 모드 결측에 따른 민감도 분석
두 번째 실험은 상시진동으로 인해 실제 가진이 잘 안되는 구조물의 특정 모드를 모사한다. 이에 특정 모드(변수)에 해당하는 열에 결측이 집중적으로 발생하는 구조적 결측의 형태를 모사하였다.
∙ 결측이 발생하는 방식(패턴)이 성능에 미치는 영향을 분석함. 2개의 모드를 랜덤으로 선택하여 선택된 모드에 해당되는 데이터만을 결측률만큼 무작위로 제거하여 결측을 부여하는 mode-selected 방식을 결측률 20%로 고정한 상태에서 FAR과 DR을 측정하여 각 기법들의 성능을 비교함
3.3.3 실제 조건의 결측치 모사
실험 결과의 우연성을 배제하고 통계적 신뢰도를 확보하기 위해, 위에서 설계된 모든 시나리오는 서로 다른 랜덤 시드(random seed)를 부여하여 총 20회 반복 수행하였다. 최종 성능은 이 20회 결과의 평균값을 사용하였다.
4. 수치적 검증 결과
4.1 이상상태 탐지 성능 평가
Table 1과 Table 2는 3.3절에서 설계한 다양한 결측 시나리오(결측률, 결측 유형)와 두 가지 임계값(95%, 99%) 조건에서 세 방법론(KNN, MICE, PPCA)의 오경보율(FAR)과 탐지율(DR)을 비교한 결과이다. 손상 시나리오 #1(급격한 손상)에 대해 각 기법을 적용한 결과, 이상탐지 정확도 측면에서는 세 방법론 간에 유의미한 성능 차이가 발견되지 않았다. 특정 방법이 일관된 우위를 보이는 대신, 각 시나리오에 따라 성능이 미세하게 변동하는 양상을 보였다. 구체적인 결과는 다음과 같다.
∙ Table 4(95% 임계값): 세 방법론 모두 5~6% 범위의 낮은 오경보율(FAR)과 95% 이상의 매우 높은 탐지율(DR)을 기록함. 이 성능은 결측률이 10%에서 30%로 증가하거나 결측 유형(MCAR, Mode-selected)이 바뀌어도 큰 저하 없이 안정적으로 유지함. 이는 세 방법론 모두 다양한 결측 환경에서 강건성(Robustness)을 확보했음을 보여줌
∙ Table 5(99% 임계값): 임계값을 99%로 상향 조정하면 예상대로 모든 방법론의 오경보율(FAR)이 1%대로 크게 감소함. 동시에 탐지율(DR)은 여전히 95% 이상(결측률 30% 제외)의 높은 수준을 유지하며, 설정된 임계값이 통계적으로 신뢰할 수 있음을 확인함
Table 4.
Anomaly detection results in Damaged Scenario #1 (Threshold 95%, repeated 20 times)
Table 5.
Anomaly detection results in Damaged Scenario #1 (Threshold 99%, repeated 20 times)
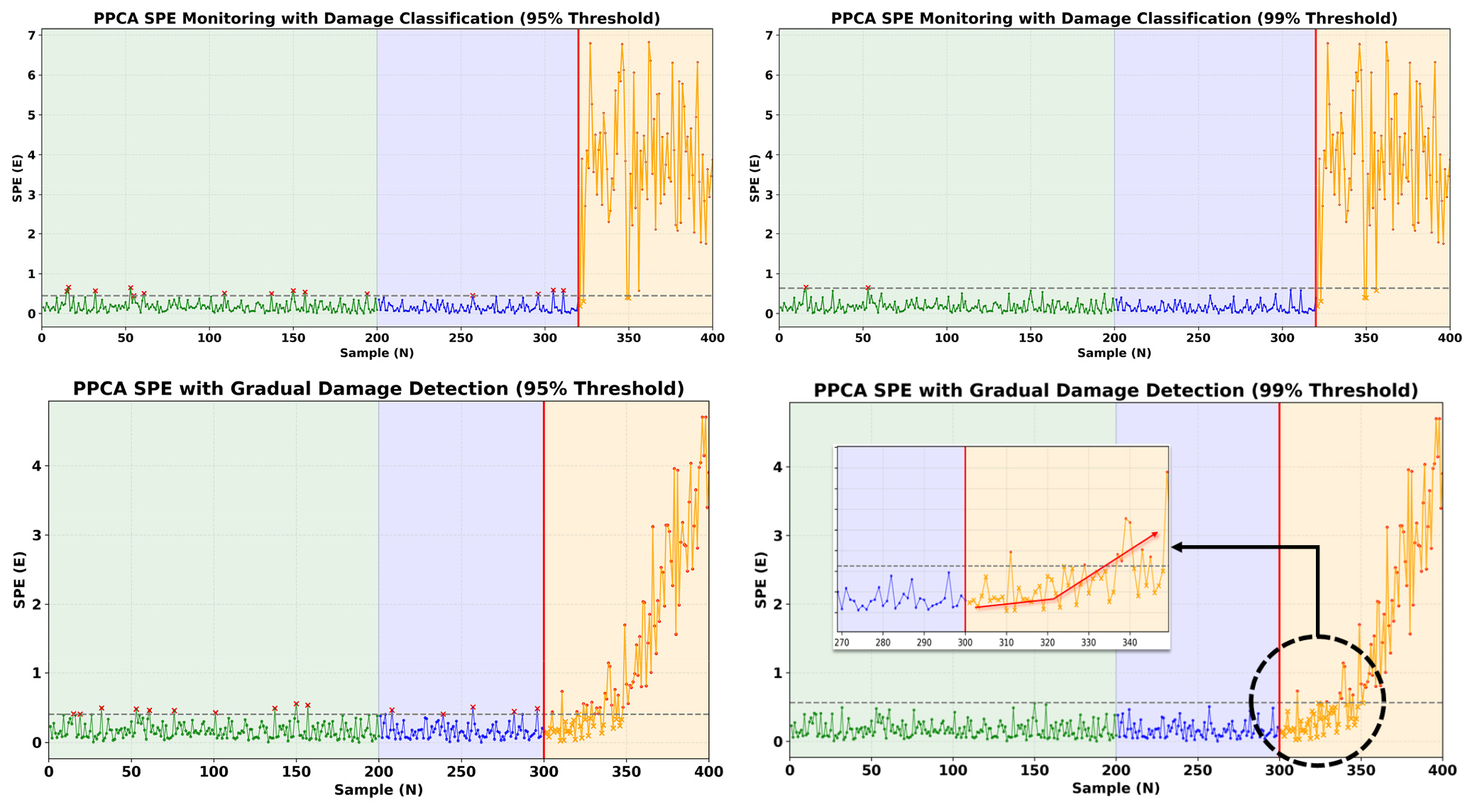
Fig. 6은 손상시나리오 별 PPCA에 기법의 성능을 보여준다. 손상 시나리오 #1(갑작스러운 손상)이 발생할 경우, 95%이나 99%의 임계값에서도 성공적으로 손상을 탐지하는 것을 확인하였다(Fig. 6의 상단). 반면, Fig. 6의 하단에서 보여지듯이 손상 시나리오 #2(점진적 손상)이 발생할 경우 즉각적인 손상 탐지가 어려운 것을 확인할 수 있다. 이는 온라인 학습 기반으로 기저 모델이 갱신되는 특성에 의해 점진적인 손상의 경우, 이를 자연스러운 변화로 인식하는 문제로 인한 결과이다. 온라인 학습 기반 PCA 기법의 경우, 이러한 점진적인 손상을 확인하는데 한계점 존재한다.
4.2 연산 복잡도 평가
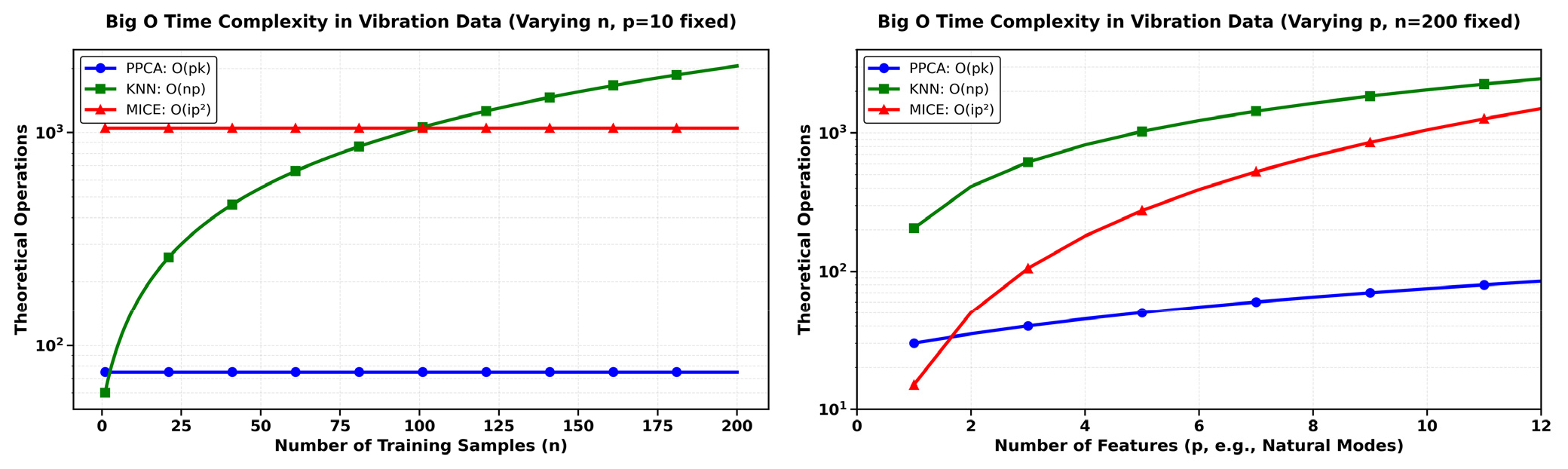
모니터링 시스템은 시간이 경과함에 따라 계측 데이터가 지속적으로 누적되어 처리해야 할 데이터의 양이 방대해지는 특성을 가진다. 따라서 알고리즘의 정확도만큼 중요한 평가지표는 연산 복잡도이다. 이를 정량적으로 평가하기 위해 본 연구에서는 Big O 표기법을 도입하였다. Big O 표기법은 입력 데이터의 크기가 증가함에 따라 알고리즘의 실행 시간이 어떻게 변화하는지를 나타내는 점근적 상한을 의미한다(Cormen et al. 2009). 이는 데이터가 실시간으로 축적되는 장기 모니터링 상황에서 알고리즘의 연산 부하가 기하급수적으로 증가하는지, 혹은 안정적으로 유지되는지를 예측하는 데 필수적인 지표이다. 각 알고리즘의 연산 복잡도를 이론적으로 분석하였으며, 분석을 위한 주요 변수는 는 선택된 주성분 수, 은 훈련 샘플 수, 는 반복 횟수, 는 고유모드의 개수(특징 수)를 의미한다. 연산 복잡성은 PPCA는 , KNN는 , Mice는 로 표현된다. Fig. 7은 이러한 연산 복잡도를 과 의 변화에 따라 시각화한 결과이다. 이를 정리하면 다음과 같은 결론을 도출하였다. 여기서 Fig. 7의 y축은 로그 스케일을 따른다.
∙ KNN()의 연산량은 의 증가에 정비례하여 민감하게 증가함(Fig. 6 좌측 빨간색)
∙ PPCA()와 MICE()의 연산량은 의 크기와 무관하게 일정함(Fig. 6 좌측 파란색 및 빨간색)
∙ Fig. 6 좌측의 결과는 의 증가에 KNN 방식은 계산 비용이 급증하는 한계가 존재함. 반면 PPCA와 MICE는 SHM 시스템의 온라인 학습 환경에서 압도적으로 유리함을 보여줌
∙ MICE()는 특징 수 에 대해 이차적(quadratic) 의존성을 가짐. 이는 각 반복마다 개의 모든 특징에 대해 조건부 회귀를 수행하기 때문으로, 분석할 모드의 수가 많은 고차원 데이터에서는 계산 비용이 급증할 수 있음을 시사함. 반면 PPCA와 KNN은 에 대해 선형적 복잡도를 가짐
∙ PPCA는 KNN과 MICE 대비 온라인 학습 환경에서 상대적으로 낮은 연산 복잡도를 가짐
4. 결 론
본 연구는 진동 기반 구조물 건전성 모니터링(SHM)의 장기 이력에서 발생하는 누락된 모드 정보(결측치)가 존재할 때 적용가능한 PCA 기반 이상탐지 기법들을 온라인 학습 환경 하 탐지 성능과 연산복잡도를 비교 분석하였다. 이를 위해 사전 대치 기반 PCA(KNN, MICE)와 확률적 PCA(PPCA) 방법론을 고려하였으며 다양한 수치검증 시나리오를 토대로 다음의 핵심 결론을 도출하였다.
1) 이상탐지 정확도 (대등): 다양한 결측률(10~30%)과 결측 유형(MCAR, Mode-selected) 시나리오에서 오경보율(FAR)과 탐지율(DR)을 비교한 결과, 세 방법론 모두 통계적으로 대등하며 강건한 탐지 성능을 보였다. 이는 PPCA가 결측치를 내부적으로 처리하면서도, 정교한 사전 대치 기법들과 동등한 수준의 정확도를 달성함을 의미한다.
2) 계산 효율성 (PPCA 우위): 탐지 정확도와 달리 계산 효율성에서는 방법론 간의 명확한 차이가 확인되었다. 온라인 학습 환경(누적 샘플 수 증가)을 가정한 시간 복잡도 분석 결과, PPCA()는 의 증가에 연산량이 영향을 받지 않아(에 의존적인 KNN() 대비) 압도적인 확장성(Scalability)을 보인다. 또한 사용되는 모드의 수에 따라 PPCA와 KNN이 에 대해 선형적 복잡도를 가진다. 반면 MICE()는 특징 수 에 대해 이차적(quadratic) 의존성을 가진다. 따라서 PPCA는 KNN과 MICE 대비 상대적으로 낮은 연산 복잡도를 가진다.
본 연구 결과는 단순 삭제나 고정값 대치(Imputation-based PCA)의 한계를 넘어 확률적 모델(PPCA)을 활용한 강건한 이상탐지 프레임워크가 적합한다는 것을 도출하였다. 비록 탐지 정확도는 대등했으나, 온라인 SHM 시스템의 실무적 적용에 필수적인 계산 효율성과 확장성 측면에서 PPCA가 가장 적합한 대안임을 입증하였다. 위 결과는 유한요소모델과 환경변수(온도)를 기반으로 한 수치 검증 실험이라 실제 교량의 복잡성을 모사하는데 한계가 있다. 향후 연구는 실제 교량 등에서 계측된 현장 데이터를 활용하여 제안된 방법론을 검증하고, 실시간 동적 환경 변화에 대응할 수 있는 온라인 학습 시스템으로 발전하고자 한다. 이는 향후 구조물 안전 관리 분야 기술의 실무 활용성 향상에 크게 기여할 것으로 기대된다.
