

1. 서 론
2. 머신러닝 및 딥러닝 기반 예측 기법
2.1 XGBoost (Extreme Gradient Boosting)
2.2 DNN (Deep Neural Network)
2.3 DLN (Deep Lattice Network)
3. 교량 점검 데이터 구축 및 전처리
3.1 데이터 출처 및 구성
3.2 데이터 전처리
3.3 학습 변수 선정
4. 초기 예측 모델 개발
4.1 XGBoost와 DNN 성능 비교
4.2 데이터 증강 기법 통한 XGBoost 기반 모델 개선
5. DLN 기반 단조성 제약 모델 개발
5.1 연구 개요
5.2 DLN 모델의 구조 및 특징
5.3 데이터 증강 기법 적용한 DLN 모델 개발
6. 결 론
7. 향후 연구 방향
1. 서 론
국내 고속도로 교량은 1970년대부터 건설되어 현재 설계 내구연한에 근접하거나 초과하고 있으며, 지속적인 교통하중과 환경적 열화요인으로 노후화가 가속화되고 있다. 교량의 노후화는 공공안전과 직결되는 중요한 사회적 이슈로, 현행 관리 체계에서는결함도지수(Defect Index, DI)를 통해 교량의 상태를 정량적으로 평가하고 있다. Table 1과 같이 결함도지수는 0에서 1 사이의 값으로 산정되며, 이를 기준으로 상태 등급이 A등급(우수)부터 E등급(불량)까지 5단계로 분류된다. 특히 결함도지수 0.49 이상인 D등급(미흡)은 주요 부재에 결함이 발생하여 긴급한 보수・보강 조치가 필요한 상태를 의미한다. 그러나 현재의 점검 체계는 교량의 현재 상태 진단에 중점을 두어, 이러한 D등급 도달 시점을 사전에 예측하고 선제적으로 대응하는 데 한계가 있다.
Table 1.
Bridge condition grade classification by defect index
이러한 배경에서 교량의 미래 성능을 예측할 수 있는 데이터 기반 모델 개발이 필요하다. 교량 점검 데이터를 활용한 성능 예측 연구는 국내외에서 활발히 진행되어 왔다. Choi et al.(2025)은 LightGBM 기반 교량 성능 예측 모델로 평균 88% 이상의 정확도를 달성하였으며, Manik and Sabarethinam(2023)은 교량 점검 자료를 활용하여 머신러닝 기반 부재 조건등급 예측 모델을 제시하였으며, Wellalage et al.(2020)은 시계열 점검 데이터를 이용한 Markov chain 기반 열화모델을 통해 교량 구성요소의 상태변화를 추정하였다. 나아가 교량 점검자료 기반 상태 예측 연구는 다양한 기계학습 및 딥러닝 기법으로 확장되고 있다. 인공신경망을 활용한 교량 상태평가 방법이 제안된 바 있으며(Oh et al., 2010), NBI 및 요소 기반 상태정보로 조건등급을 예측한 연구도 보고되었다. 또한 국내에서도 교량 안전등급 분류 및 결함도지수 예측을 위한 기계학습 모델이 제시되었고(Hong and Jeon, 2022; Lee et al., 2024), 시계열 특성을 고려한 딥러닝 기반 성능 예측 모델도 제안되었다(Choi et al., 2023).
그러나 이러한 선행 연구들은 주로 학습 데이터 범위 내에서의 예측 성능에 집중하였으며, 학습 범위를 벗어난 외삽 구간에서의 예측 정확도 검증은 부족하다. DNN과 XGBoost 같은 전통적인 모델들은 고결함도 구간에 대한 외삽 추론 시 예측값이 특정 값으로 수렴하거나 불안정한 경향을 보인다. 본 연구의 초기 실험에서도 XGBoost가 높은 예측 정확도를 보였으나, 장기 예측 시 D등급 임계값 근처에서 예측 곡선이 수렴하여 실제 D등급 도달 시점을 예측하지 못하는 문제가 확인되었다.
본 연구의 목적은 고속도로 교량의 결함도지수와 D등급 도달 시점을 정확히 예측할 수 있는 딥러닝 기반 모델을 개발하여 교량 관리자가 선제적으로 보수・보강 계획을 수립하고 자원을 효율적으로 배분하도록 지원하는 것이다. 본 연구는 기존 연구의 외삽 추론 한계를 극복하기 위해 다음과 같은 차별화된 접근을 제시한다. 첫째, 합성 데이터를 활용한 체계적인 외삽 능력 검증 프레임워크를 구축한다. 둘째, 단조성 제약을 적용할 수 있는 DLN 모델을 도입하여 외삽 구간에서의 예측 안정성을 향상시킨다. 셋째, 데이터 증강 등 다양한 기법을 적용하여 고결함도 구간의 예측 정확도를 개선한다.
본 논문은 다음과 같이 구성된다. 제2장에서는 이론적 배경을, 제3장에서는 데이터 구축 및 전처리 과정을, 제4장에서는 XGBoost 기반의 초기 연구 결과를, 제5장에서는 DLN 기반 모델의 개발과 성능 평가를, 제6장에서는 모델의 종합적 분석을, 제7장에서는 연구 결과 요약과 향후 연구 방향을 제시한다.
2. 머신러닝 및 딥러닝 기반 예측 기법
2.1 XGBoost (Extreme Gradient Boosting)
XGBoost는 Gradient Boosting 알고리즘을 기반으로 한 앙상블 학습 기법으로, 여러 개의 약한 학습기(weak learner)를 순차적으로 결합하여 강력한 예측 모델을 구축한다. XGBoost는 손실 함수(loss function)를 최소화하는 방향으로 트리를 순차적으로 추가하는 방식으로 작동한다. 번째 반복에서의 예측값은 식 (1)과 같이 표현된다. 여기서 는 번째 트리이며, 각 트리는 이전 모델의 잔차(residual)를 학습하여 예측 성능을 점진적으로 향상시킨다.
XGBoost는 여러 가지 장점을 가지고 있다. 첫째, 앙상블 기법을 통해 개별 모델의 약점을 보완하여 높은 예측 정확도를 달성한다. 둘째, 정규화(regularization) 항을 포함하여 과적합을 방지하고 모델의 일반화 성능을 향상시킨다. 셋째, 병렬 처리와 트리 가지치기(pruning) 기법을 적용하여 빠른 학습 속도를 제공한다. 넷째, 결측값을 자동으로 처리할 수 있는 기능이 내장되어 있어 데이터 전처리 부담을 줄일 수 있다.
2.2 DNN (Deep Neural Network)
DNN은 다층 구조의 인공신경망으로, 입력층(input layer), 여러 개의 은닉층(hidden layer), 출력층(output layer)으로 구성된다. 각 층은 다수의 뉴런(neuron)으로 이루어져 있으며, 뉴런 간의 연결 가중치(weight)를 학습하여 복잡한 비선형 관계를 모델링한다. DNN의 학습은 역전파(backpropagation) 알고리즘을 통해 이루어진다. 예측값과 실제값 사이의 오차를 계산한 후, 이 오차를 출력층에서 입력층 방향으로 전파하면서 각 층의 가중치를 업데이트한다. 이 과정은 순전파(Forward propagation), 손실 계산, 역전파(Backpropagation), 최적화의 단계로 구성된다.
먼저 순전파 단계에서는 입력 데이터가 각 층을 거치면서 예측값을 생성한다. 이어서 예측값과 실제값의 차이를 손실 함수로 계산하고, 역전파 단계에서 손실의 기울기를 계산하여 가중치를 업데이트한다. 마지막으로 경사하강법(Gradient Descent) 등을 이용하여 가중치를 조정하는 최적화 과정을 거친다. 은닉층에서는 비선형 활성화 함수를 사용하여 모델의 표현력을 높인다. 대표적인 활성화 함수로는 ReLU(Rectified Linear Unit), Sigmoid, Tanh 등이 있으며, 이러한 일반적인 심층 신경망 구조와 학습 절차는 Aggarwal(2018)에 자세히 정리되어 있다. 본 연구에서는 은닉층에 ReLU를 적용하였다.
2.3 DLN (Deep Lattice Network)
DLN은 Google Research에서 개발한 해석 가능한 딥러닝 모델로, 입력 변수 간의 관계를 격자(lattice) 구조로 표현하여 단조성(monotonicity) 제약을 적용할 수 있는 특징이 있다. 교량 열화 예측과 같이 물리적 제약 조건이 명확한 문제에 특히 유용하다. DLN은 PWL(Piecewise Linear) 보정 계층, Calibrated Lattice 계층, 단조성 제약의 세 가지 주요 구성 요소로 이루어진다. PWL 보정 계층은 입력 변수를 구간별 선형 함수로 변환하여 정규화하며, Calibrated Lattice 계층은 격자 구조를 통해 입력 변수 간의 상호작용을 학습한다. 단조성 제약은 특정 입력 변수가 증가할 때 출력도 증가하거나 감소하도록 강제하는 역할을 한다.
또한 DLN은 여러 개의 격자 모델을 앙상블하여 예측 성능을 향상시킬 수 있다. 각 격자는 입력 변수의 부분집합을 사용하여 학습되며, 최종 예측값은 모든 격자의 출력을 결합하여 생성된다. 이러한 앙상블 기법은 모델의 표현력을 높이면서도 단조성 제약을 유지할 수 있다.
3. 교량 점검 데이터 구축 및 전처리
3.1 데이터 출처 및 구성
본 연구는 한국도로공사의 정밀안전점검 및 정밀안전진단 데이터베이스를 활용하였다. 데이터는 교량 제원 및 환경 데이터(교량명, 상부구조 형식, 준공년도, 지사명, 연장, 총폭, 면적, 염화물 농도, 교통량, 차선수 등)와 교량 성능 데이터(전체등급, 결함도지수, 바닥판, 거더, 교면포장, 배수시설, 신축이음, 교량받침, 하부구조 등 부재별 상태 정보)로 구성되어 있다.
서로 다른 두 데이터 파일의 통합을 위해 공통 변수를 추출하였다. 열 이름의 공백, 개행문자, 특수문자를 제거하고 대소문자를 통일하여 정규화한 후, 교집합을 구하여 공통 변수 목록을 생성하였다. “점검시 공용년수”는 일부 데이터에서 직접 제공되지 않아 점검일자와 준공년도의 차이를 열대년 기준(365.2425일)으로 계산하여 파생 변수로 생성하였다.
3.2 데이터 전처리
원본 데이터의 점검일자와 준공년도는 YYYYMMDD, YYYY.MM, YYYY 등 다양한 형식으로 혼재되어 있어 정규화가 필요하였다. 점검일자는 YYYYMMDD 형식으로 통일하였으며, 년월만 있는 경우 교량 식별자 기반 해시 함수로 1-28일을, 년도만 있는 경우 6월 기준으로 일자를 할당하였다. 준공년도는 2단계 절차를 통해 정규화하였다. 먼저 원본 데이터를 YYYYMMDD로 변환하고(4자리 연도는 1월 1일 기본값 사용), 실패 시 “준공년도 수정”과 참조 파일의 “하자만료일” 정보를 활용한 보정 절차를 적용하였다. 정규화 규칙 적용 예시는 Table 2와 같다
Table 2.
Inspection date & construction year normalization (example)
정규화 결과 원본 8,197행 중 7,504행이 성공적으로 변환되었으며, 이를 바탕으로 공용년수를 산출하였다. 공용년수는 점검일자와 준공년도의 차이를 열대년 기준(365.2425일)으로 계산하였으며, 음수 값은 데이터 오류로 판단하여 차후 제거 처리하였다(Kim et al., 2024). 공용년수 산출 예시는 아래 Table 3와 같다.
Table 3.
Service years calculation (example)
3.3 학습 변수 선정
정밀안전점검 및 정밀안전진단 데이터베이스는 교량 제원 및 환경 데이터와 교량 성능 데이터로 구성되며, 주요 변수는 Table 4에 분류하여 정리하였다. 본 연구에서는 전체 결함도지수를 예측 대상으로 설정하고, 학습 변수 선정을 위해 주요 변수들과 결함도지수 간의 상관관계를 분석하였다.
Fig. 1(a)는 8개 주요 변수 간의 피어슨 상관계수를 히트맵으로, Fig. 1(b)는 결함도지수와 각 변수 간의 상관계수를 막대그래프로 나타낸 것이다. 분석 결과, 공용년수가 결함도지수와 가장 높은 상관관계(0.45)를 보였다. 통계적 해석 기준(Cohen, 1988)에 따르면, 복잡한 현장 데이터 분석에서 상관계수 0.30 이상은 중간 수준 이상의 상관관계(Medium effect)를, 0.10 이상은 유의미한 작은 상관관계(Small effect)를 의미한다. 따라서 공용년수의 0.45는 교량 열화 예측에 있어 매우 강력한 선형적 관계를 시사하며, 교통량(0.14), 염화물(0.12), 중차량교통량(0.11) 등도 통계적으로 유의미한 예측 인자라 할 수 있다.
이를 바탕으로 Table 4에 볼드 표시된 공용년수, 연장, 총폭, 면적, 염화물, 교통량(Annual Average Daily Traffic, AADT), 중차량교통량(Average Daily Truck Traffic, ADTT), 결함도지수를 최종 학습 변수로 선정하였다. 최종 데이터셋은 6,164개의 교량 점검 기록과 10개 변수로 구성되며, 최종 데이터셋의 예시는 Table 5와 같다.
Table 4.
Categories of bridge data used in the study
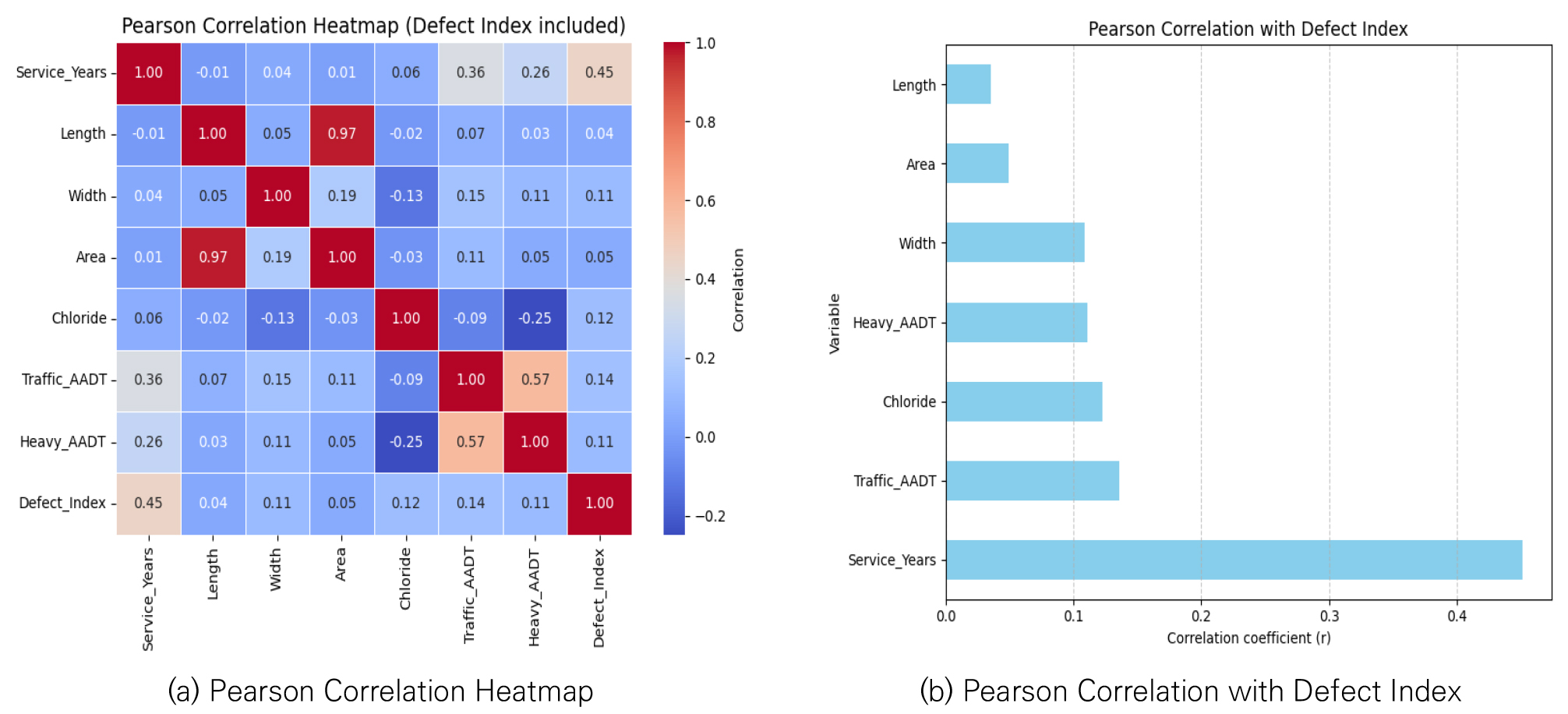
Table 5.
Final data set (example)
4. 초기 예측 모델 개발
4.1 XGBoost와 DNN 성능 비교
4.1.1 모델 선정 배경
교량 결함도지수 예측을 위한 초기 모델로 XGBoost와 DNN을 선정하였다. 이 두 모델은 서로 다른 학습 메커니즘을 가지면서도 비선형 관계를 효과적으로 모델링할 수 있는 대표적인 알고리즘이다.
XGBoost는 Gradient Boosting 기반의 앙상블 학습 기법으로 여러 개의 의사결정트리를 순차적으로 결합하여 강력한 예측 모델을 구축한다. 정규화를 통한 과적합 방지, 빠른 학습 속도, 결측값 자동 처리, 변수 중요도 제공 등의 장점이 있어 표 형태의 구조화된 데이터에서 뛰어난 성능을 보인다. DNN은 다층 구조의 인공신경망으로 복잡한 비선형 관계를 학습할 수 있는 강력한 표현력을 가지며, 여러 은닉층을 통해 입력 데이터의 고차원적 특징을 자동으로 추출한다. 본 연구에서는 한국 고속도로 교량 데이터의 특성과 규모를 고려하여 두 모델의 성능을 직접 비교함으로써 본 연구 데이터에 최적화된 모델을 선정하고자 하였다.
4.1.2 DNN 모델 구조 및 성능평가
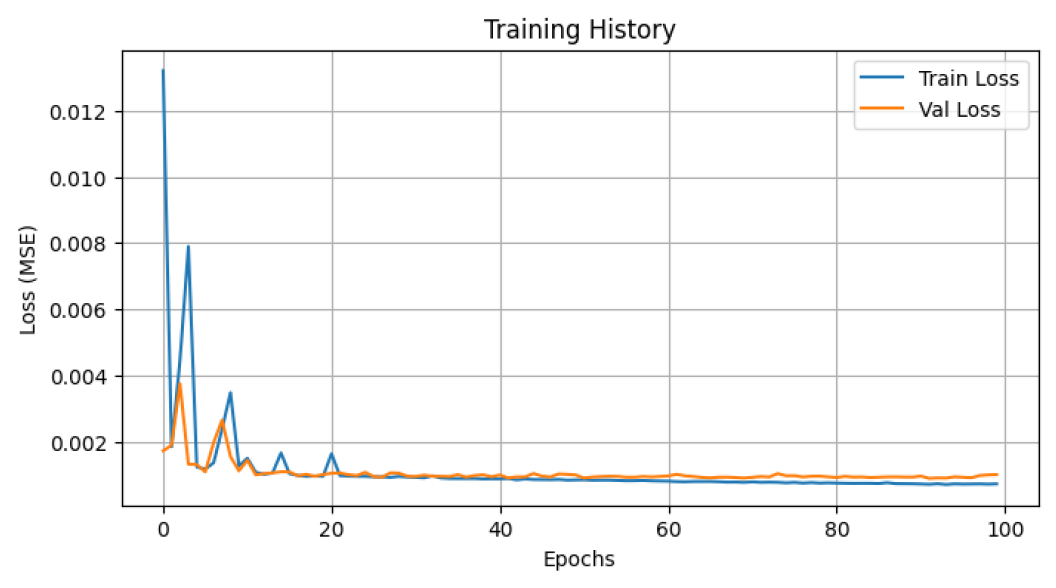
DNN 모델은 TensorFlow/Keras를 사용하여 구현하였다. 최적의 네트워크 구조를 도출하기 위해 은닉층의 수(1~3개)와 뉴런 수(32~128개), 학습률(0.01~0.0001)에 대한 사전 실험을 수행하였으며, 그 결과 가장 우수한 성능과 학습 안정성을 보인 입력층(7개 변수), 두 개의 은닉층(64, 32 뉴런, ReLU), 출력층(1뉴런, 선형) 구조를 최종 선정하였다. 학습에는 Adam 옵티마이저와 MSE 손실 함수를 적용하였고, 최대 100 에포크, 배치 크기 8, 검증 데이터 20% 조건으로 학습을 수행하였다. 이때 학습 곡선 분석 결과, 모델은 약 60~70 에포크 구간에서 손실이 안정화되며 수렴하는 경향을 보였고, 그 양상은 Fig. 2에 제시하였다.
성능 평가 결과는 Table 6과 같다. 학습 데이터에 대해 MAE 0.0212, MSE 0.0008, R² 0.429를, 테스트 데이터에 대해 MAE 0.0235, MSE 0.0010, R² 0.361을 기록하였다. R²가 다소 낮은 것은 데이터가 건전한 상태에 집중되어 분산이 작기 때문으로, NBI 데이터를 활용한 Bektaş(2017)의 연구에서도 바닥판(Deck) 및 하부구조(Substructure) 예측 모델의 Generalized R²가 0.30~0.38 수준으로 보고된 바 있다. 해당 연구에서는 이 수치를 두고도 예측 정확도가 충분하다고 평가하였으며, 본 연구 역시 실무적으로 중요한 절대 오차(MAE 0.0235)가 낮으므로 충분한 예측 성능을 확보한 것으로 판단된다.
Table 6.
Training and test performance of the DNN model
| Performance metrics | Train | Test |
| MAE | 0.0212 | 0.0235 |
| MSE | 0.0008 | 0.0010 |
| R-squared | 0.4289 | 0.3606 |
4.1.3 XGBoost 모델 구조 및 성능평가
XGBoost 모델은 GridSearchCV를 사용하여 하이퍼파라미터를 최적화하였다. 3-fold 교차 검증을 통해 트리의 개수(Number of estimators), 최대 깊이(Maximum depth), 학습률(Learning rate), 서브샘플 비율(Subsample ratio), 특성 샘플링 비율(Column subsampling ratio by tree) 등의 최적 조합을 탐색하였다. XGBoost는 트리 기반 앙상블 모델이며, 앙상블 학습의 개념은 신경망 분야에서도 활용된 바 있다(Alam et al., 2020).
최적 하이퍼파라미터로 학습된 XGBoost 모델의 성능을 평가한 결과, 학습 데이터에 대한 MAE는 0.0217, MSE는 0.0009, R²는 0.413을 기록하였으며, 테스트 데이터에 대해서는 MAE 0.0214, MSE 0.0008, R² 0.415를 나타냈다. 학습 및 테스트 성능 지표는 Table 7에 정리하였다. 학습과 테스트 성능이 거의 동일한 것은 모델이 과적합 없이 안정적으로 학습되었음을 의미하며, 일반화 능력이 우수함을 보여준다.
Table 7.
Training and test performance of the XGBoost model
| Performance metrics | Train | Test |
| MAE | 0.0217 | 0.0214 |
| MSE | 0.0009 | 0.0008 |
| R-squared | 0.4134 | 0.4149 |
4.1.4 성능 비교 및 기본 모델 선정
두 모델의 성능을 정량적으로 비교하면, 테스트 데이터 기준으로 XGBoost의 R²는 0.415로 DNN의 0.361보다 높았으며, MAE는 0.0214로 DNN의 0.0235보다 낮았고, MSE도 0.0008로 DNN의 0.0010보다 낮았다. 모든 평가 지표에서 XGBoost가 DNN보다 우수한 성능을 보였다.
특히 주목할 점은 XGBoost의 학습-테스트 성능 일관성이다. DNN은 학습 R²가 0.429로 테스트 R² 0.361보다 높아 과적합 경향을 보인 반면, XGBoost는 학습 R² 0.413과 테스트 R² 0.415가 거의 동일하여 안정적인 일반화 능력을 나타냈다.
이러한 종합적인 평가를 바탕으로 본 연구에서는 XGBoost를 초기 모델로 선정하였다. XGBoost는 DNN보다 높은 예측 정확도, 안정적인 일반화 능력, 빠른 학습 속도 등에서 우수한 특성을 보였다. 따라서 다음 절에서는 XGBoost 모델의 외삽 예측 한계를 확인하고 이를 개선하기 위해 데이터 증강 기법을 적용한 과정을 기술한다.
4.2 데이터 증강 기법 통한 XGBoost 기반 모델 개선
4.2.1 데이터 불균형 문제
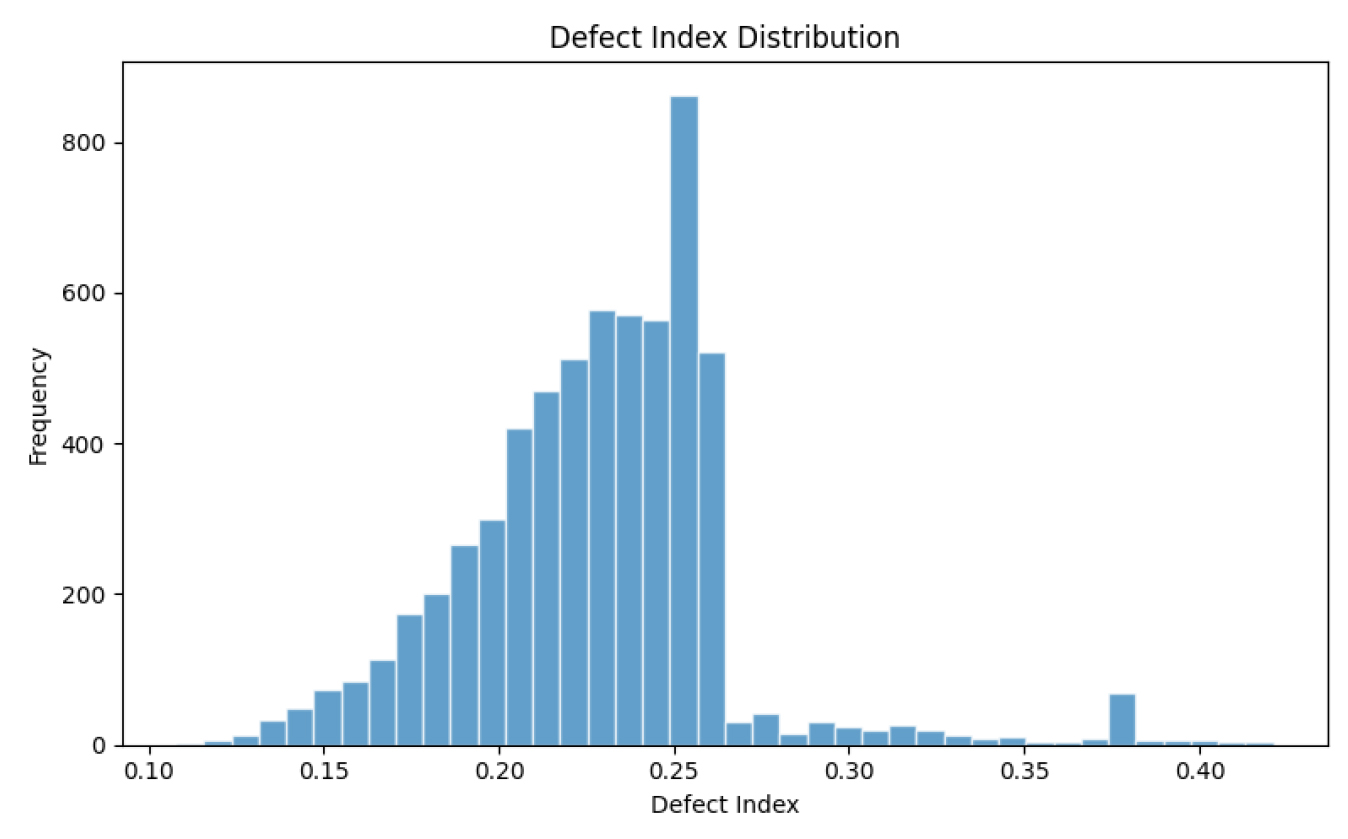
4.1절에서 선정한 XGBoost 모델은 전체 테스트 데이터에 대해 R² 0.415의 양호한 성능을 보였으나, 이는 주로 A,B등급 구간의 데이터가 대부분을 차지하기 때문에 나타난 결과이다. 최종 데이터셋 6,164개를 결함도지수 기준으로 분석한 결과, 결함도지수 0.26 미만의 A,B등급에 해당하는 교량이 5,798개로 전체의 약 94%를 차지하는 반면, 결함도지수 0.26 이상의 C등급 이상 교량은 366개에 불과하여 전체의 약 6%만을 차지하는 것으로 나타났다. 이러한 심각한 데이터 불균형은 Fig. 3에서도 확인되며, 모델이 고결함도 구간의 열화 패턴을 제대로 학습하지 못하게 만드는 주요 원인이다.
특히 본 연구의 최종 목표인 D등급 도달 시점 예측은 결함도지수 0.49 이상 구간에 대한 정확한 예측을 필요로 하는데, 학습 데이터에 C등급 이상의 샘플이 극히 부족한 상황에서는 모델이 해당 구간으로의 외삽 예측을 수행할 때 신뢰할 수 있는 결과를 생성하기 어렵다. 실제로 초기 모델을 사용하여 장기 예측 시뮬레이션을 수행한 결과, 예측값이 결함도지수 0.30~0.35 수준에서 수렴하여 D등급 임계값에 도달하지 못하는 현상이 관찰되었다. 이는 모델이 학습 데이터에서 충분히 관찰되지 않은 고결함도 구간에 대해서는 적절한 예측을 생성하지 못함을 의미한다.
4.2.2 데이터 증강 기법의 설계
고결함도 구간 데이터의 부족 문제를 완화하기 위해 Gaussian noise 기반의 데이터 증강 기법을 적용하였다. 먼저 결함도지수 0.26 이상의 희소 데이터 366개를 학습용과 테스트용으로 50:50 비율로 분할하여 각각 183개씩 할당하였으며, 정상 데이터 5,798개는 70:30 비율로 분할하여 학습용 4,058개, 테스트용 1,740개를 할당하였다. 정상 데이터와 달리 희소 데이터에 50:50 비율을 적용한 것은 평가의 신뢰성을 확보하기 위함이다. 희소 데이터의 절대량이 부족한 상황에서 일반적인 70:30 비율을 적용할 경우 테스트 샘플 수가 지나치게 적어 통계적 유의성을 확보하기 어렵다. 따라서 학습 데이터의 양적 손실을 감수하더라도 테스트셋의 규모를 최대한 확보하여 고결함도 구간에 대한 예측 성능을 보다 엄밀하게 검증하고자 하였다.
증강은 희소 학습 데이터 183개에 대해서만 수행하였는데, 이때 각 변수의 물리적 크기(Scale) 차이를 반영하기 위해 '적응적 노이즈 적용' 방식을 사용하였다. 구체적으로는 희소 데이터셋의 모든 연속형 입력 변수와 출력 변수(결함도지수)에 대해 각각의 표준편차를 계산한 후, 평균이 0이고 표준편차가 해당 변수 표준편차의 10%인 정규분포(Gaussian Distribution)를 따르는 노이즈를 생성하여 Table 8과 같이 원본 값에 더하였다. 이 방식을 통해 스케일이 큰 변수에는 상대적으로 큰 노이즈가, 스케일이 작은 변수에는 작은 노이즈가 부여되어 데이터의 통계적 특성을 유지하면서 다양성을 확보하였다. 증강 배수는 5, 10, 20, 30, 40, 50, 60, 70의 8가지 값으로 설정하여 실험을 수행하였으며, 최종 학습 데이터는 정상 학습 데이터 4,058개, 원본 희소 학습 데이터 183개, 그리고 증강 데이터로 구성된다.
Table 8.
Example of data augmentation for Seopyeong Bridge (Suncheon)
4.2.3 성능 평가 결과
Table 9는 학습에 관여하지 않은 독립적인 테스트 데이터(1,923개)를 대상으로 수행한 성능 평가 결과이다. 본 연구는 데이터 불균형 해소를 통한 고결함도 구간의 예측력 확보를 목표로 하므로, 'Validation MAE'를 최우선 판정 기준으로 삼았다.
분석 결과, 증강 배수가 5배에서 70배로 증가함에 따라 Validation MAE는 0.0569에서 0.0357로 꾸준히 감소하고 Test R²는 0.750까지 상승하며 최적의 성능을 기록하였다. 반면, 70배를 초과하는 80배와 90배 구간에서는 Validation MAE가 소폭 증가하고 Test R²는 0.545, 0.392로 급락하여 과도한 증강이 오히려 모델의 과적합을 초래함을 확인하였다.
결과적으로 희소 구간 예측 성능(Validation MAE)과 전체 모델의 설명력(Test R²) 균형이 가장 우수한 70배를 최적 모델로 선정하였다. 다만, 최적 모델에서도 희소 구간의 오차가 전체 평균 대비 약 2.4배 높다는 점은 여전히 고결함도 구간의 예측 난이도가 높음을 시사하며, 이는 향후 해결해야 할 과제로 남아 있다.
Table 9.
Performance evaluation results of XGBoost models by augmentation ratio
4.2.4 예측 데이터에 대한 적용 및 D등급 도달 시뮬레이션
학습된 모델을 예측용 전체 교량 데이터 9,564개에 적용하였다. 예측 데이터의 현재 결함도지수 분포는 A등급 22.6%, B등급 74.4%, C등급 3.0%로 대부분의 교량이 양호한 상태이며, 현재 공용년수는 평균 19.4년으로 1년부터 56년까지 분포하고 있다.
데이터 증강 배수 70으로 학습된 최적 모델을 사용하여 D등급 도달 시점을 추정하는 시뮬레이션을 수행한 결과, 전체 9,564개 교량 중 단 6개(0.06%)만이 D등급에 도달할 것으로 예측되었다. D등급 도달이 예측된 6개 교량은 현재 결함도지수 평균 0.431로 이미 C등급 중상위 수준이었으며, 평균 34.2년의 공용년수에서 D등급에 도달할 것으로 예측되었다. 등급별 예측 결과는 Table 10에 정리하였다
반면 D등급 미도달이 예측된 9,558개 교량의 현재 결함도지수 평균은 0.179로 대부분 A, B등급에 해당하였으며, 최대 예측 결함도지수는 평균 0.247로 여전히 B등급 수준에 머물렀다. 최대 예측 결함도지수가 0.45 이상(D등급 근접)으로 예측된 교량은 15개(0.2%)에 불과하였고, 대다수인 7,322개(76.5%)는 0.30 미만으로 예측 곡선이 B등급 이하에서 수렴하였다.
이러한 결과는 데이터 증강 기법이 학습 데이터 범위 내의 예측 성능은 개선하였으나, 학습 범위를 크게 벗어난 D등급 구간으로의 외삽 예측에는 여전히 심각한 한계가 있음을 보여준다. 특히 현재 C등급 중상위 교량조차도 대부분 D등급 도달을 예측하지 못하여, 모델이 고결함도 구간에서 열화 진행을 과소평가하는 경향이 있다.
Table 10.
Grade prediction summary
| Item | Value |
| Total Bridges | 9,564 |
| Grade A (DI<0.13) | 679 (7.1%) |
| Grade B (0.13≤DI<0.26) | 4,367 (45.6%) |
| Grade C (0.26≤DI<0.49) | 4,523 (47.3%) |
| Grade D (0.49≤DI<0.79) | 6 (0.1%) |
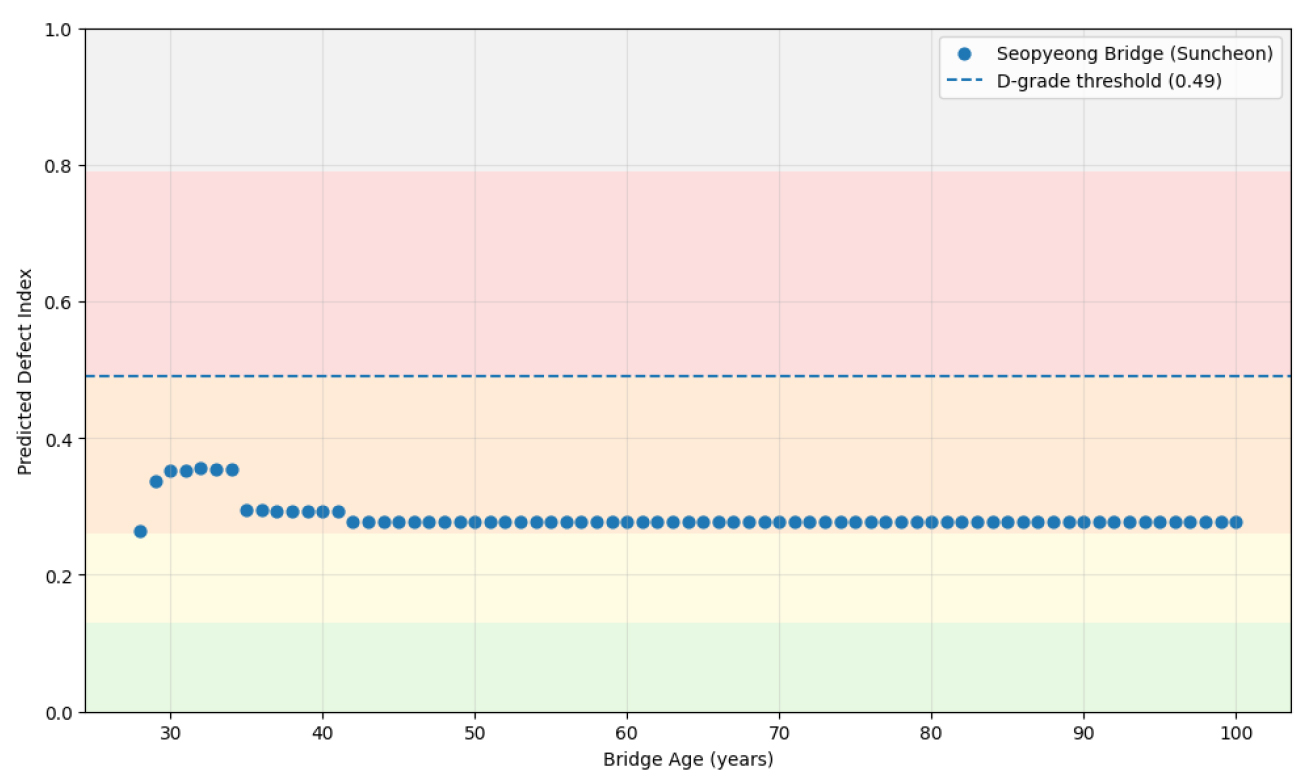
Fig. 4는 XGBoost 모델의 대표 교량인 서평교(순천)에 대한 장기 열화 예측 결과를 나타낸 것이다. 배경색은 결함도지수 범위별 등급(A~E)을 구분하며, 현재 공용년수 28년(결함도지수 0.195, B등급)에서 시작하여 32년차에 최대값 0.356(C등급)에 도달한 후 오히려 감소하여 0.28~0.30 수준에서 수렴하는 것으로 나타났다. 예측 곡선은 D등급 임계값(0.49, 점선)에 도달하지 못하며, 일부 구간에서 공용년수 증가에도 결함도지수가 감소하는 비물리적 패턴을 보인다. 이는 XGBoost가 학습 데이터 범위를 벗어난 외삽 구간에서 예측값이 수렴하는 근본적인 한계를 나타낸다.
4.2.5 데이터 증강의 효과 및 한계
데이터 증강 기법은 고결함도 구간 데이터의 부족 문제를 일부 완화하고 전체적인 모델 성능을 향상시키는 데 효과적이었다. 전체 테스트 R²가 증강 배수 5에서 0.499에서 증강 배수 70에서 0.750으로 향상되었으며, 희소 테스트 데이터에 대한 MAE도 0.0569에서 0.0357로 감소하는 등 정량적인 개선을 확인할 수 있었다.
그러나 근본적인 한계가 여전히 존재한다. 증강 데이터는 원본 희소 데이터의 통계적 분포 범위를 크게 벗어나지 못하며, D등급 도달 시뮬레이션 결과 전체 교량의 0.06%만이 D등급 도달로 예측되어 모델이 외삽 구간에서 결함도지수 증가를 과소평가하고 있다. 또한 희소 테스트 데이터에 대한 MAE가 여전히 전체 Test MAE의 약 2.4배 수준으로 고결함도 구간 예측 난이도가 높다는 문제는 해결되지 않았다. Gaussian 노이즈 기반 증강은 변수 간의 물리적 관계를 고려하지 않으며, 증강 배수를 크게 증가시켜도 D등급 도달 예측 비율이 거의 개선되지 않아 단순히 증강 데이터의 양을 늘리는 것만으로는 외삽 문제를 해결할 수 없다.
따라서 데이터 증강은 학습 데이터 범위 내의 성능 개선에는 효과적이지만, 실무적으로 가장 중요한 D등급 도달 시점 예측이라는 장기 외삽 문제를 근본적으로 해결하지는 못하였다. 이러한 XGBoost의 외삽 한계를 극복하기 위해 다음 절에서는 XGBoost의 단기 예측 결과들을 2차 회귀곡선으로 피팅하여 장기 열화 경향을 추정하는 접근법을 기술한다.
5. DLN 기반 단조성 제약 모델 개발
5.1 연구 개요
4장에서 XGBoost 모델의 근본적인 외삽 한계를 확인하였다. 트리 기반 모델은 학습 데이터에서 관찰되지 않은 범위의 값을 예측하지 못하고 특정 값으로 수렴하는 현상을 보였으며, 데이터 증강 기법을 적용하였음에도 불구하고 D등급 도달 시점 예측이라는 외삽 문제를 해결하지 못하였다.
본 장에서는 이러한 외삽 문제를 해결하기 위해 DLN(Deep Lattice Network) 기반 모델을 개발하고, 물리적 제약 조건인 단조성(monotonicity)을 명시적으로 모델에 반영한다. DLN은 Google Research에서 개발한 모델로, 입력 변수와 출력 변수 사이의 단조성 관계를 직접 강제할 수 있는 구조적 특징을 가지고 있다. 특히 본 연구에서는 공용년수에 대해 단조 증가 제약을 적용하여, 공용년수가 증가하면 결함도지수가 반드시 증가하거나 유지되도록 모델을 설계한다.
5.2 DLN 모델의 구조 및 특징
DLN의 핵심 특징은 단조성 제약을 수학적으로 강제할 수 있다는 점이다. PWL Calibration에서는 각 구간의 기울기를 0 이상으로 제한하고, Lattice Layer에서는 격자의 인접 꼭짓점 간 값이 비감소(non-decreasing)하도록 파라미터를 제약한다. 이러한 제약은 학습 과정과 완료 후에도 유지되어, 외삽 구간에서도 물리적으로 타당한 예측을 보장한다.
반면 XGBoost는 의사결정트리 앙상블로 학습 데이터 범위 밖의 입력에 대해 가장 가까운 리프 노드 값을 반환하므로 외삽 구간에서 예측이 포화된다. 또한 단조성을 명시적으로 강제할 수 없어 공용년수 증가 시에도 예측값이 증가하지 않는 비물리적 결과를 생성할 수 있다. DLN은 격자 구조와 PWL Calibration을 통해 외삽 구간에서도 단조성을 유지하며, 이는 교량 열화의 물리적 메커니즘과 일치하는 예측을 가능하게 한다.
5.3 데이터 증강 기법 적용한 DLN 모델 개발
5.3.1 데이터 증강의 필요성
4장의 XGBoost는 70배 증강이 최적이었으나, 본 장의 DLN은 물리적 타당성을 위해 ‘결함도지수 증가율’을 학습하면서 희소 데이터가 10개로 급감하여 일반 구간(1,535개) 대비 1:153의 극심한 불균형이 발생하였다. 경사 하강법을 쓰는 DLN은 이러한 불균형 시 희소 구간 학습을 무시하는 경향이 있다. 따라서 본 연구에서는 데이터 비율을 1:1로 맞춰 학습 기여도를 보장하고자, 희소 데이터 10개에 152배 증강을 적용하여 약 1,530개 샘플을 확보함으로써 수량적 균형을 달성하였다.
5.3.2 모델 학습 및 성능평가
152배 데이터 증강을 적용한 DLN 모델을 동일한 학습 설정(최대 600 에포크, 배치 크기 256, Early Stopping patience=20)으로 학습하였다. 학습은 74번째 에포크에서 조기 종료되었다. 학습이 완료된 모델의 성능 평가 결과는 Table 11과 같다.
Table 11.
DLN model performance (data augmented)
| Dataset | MAE | MSE | Sample Size |
| All Training Data | 0.0064 | 0.000127 | 2,452 |
| All Test Data | 0.0067 | 0.000154 | 613 |
| Rare Training Data (DI≥0.26) | 0.0027 | 0.000011 | 1,124 |
| Rare Test Data (DI≥0.26) | 0.0026 | 0.000010 | 273 |
5.3.3 D등급 도달 시뮬레이션 결과
152배 데이터 증강을 적용한 DLN 모델로 동일한 9,564개 교량에 대해 D등급 도달 시뮬레이션을 수행한 결과는 다음과 같다. 균형잡힌 데이터 증강을 적용한 결과, D등급 도달 비율이 95.82%로 감소하여 400개 교량(4.18%)이 공용년수 100년까지 D등급에 도달하지 않을 것으로 예측되었다. 이는 원본 모델(99.99%)에 비해 큰 변화이며, 모델이 고결함도 구간을 제대로 학습한 결과로 해석된다. 원본 모델과 증강 모델의 D등급 도달 여부 및 최대 예측 결함도지수 통계 비교 결과는 Table 12에 정리하였다. 최대예측값의 표준편차도 0.011로 증가하여 교량별 특성에 따른 예측 다양성이 크게 향상되었다.
Table 12.
D-Grade arrival simulation results comparison
Fig. 5는 서평교(순천)의 장기 열화 예측 곡선이다. 이 교량은 현재 공용년수 28년에서 결함도지수 0.195(B등급)의 양호한 상태에 있다. 증강 모델의 초기와 중기 구간 증가율은 각각 0.0085, 0.0092 DI/year이며, D등급 도달 시점은 62년, 최종 예측값은 0.85로 현실적인 장기 열화 수준을 예측한다. 그러나 중요한 한계점이 존재하는데, 물리적으로 교량 열화는 후기로 갈수록 가속되는 특성을 가져야 하나, 증강 모델은 중기~후기에 일정한 증가율을 유지하여 가속 패턴을 보이지 않는다. 이는 결함도지수 0.4 이상 구간의 실측 데이터가 거의 없어 D등급에서의 가속 열화 패턴을 학습할 수 없었기 때문이다.
그럼에도 불구하고 증강 모델은 고결함도 샘플 1,530개를 확보하여 보다 안정적이고 일관된 예측 패턴을 보였으며, 이는 과도한 조기 대응이나 예산 투입을 방지할 수 있다는 점에서 실무적 가치가 있다. 다만, 교량 열화의 가속적 특성을 완전히 반영하지 못한 것은 향후 과제로 남는다.
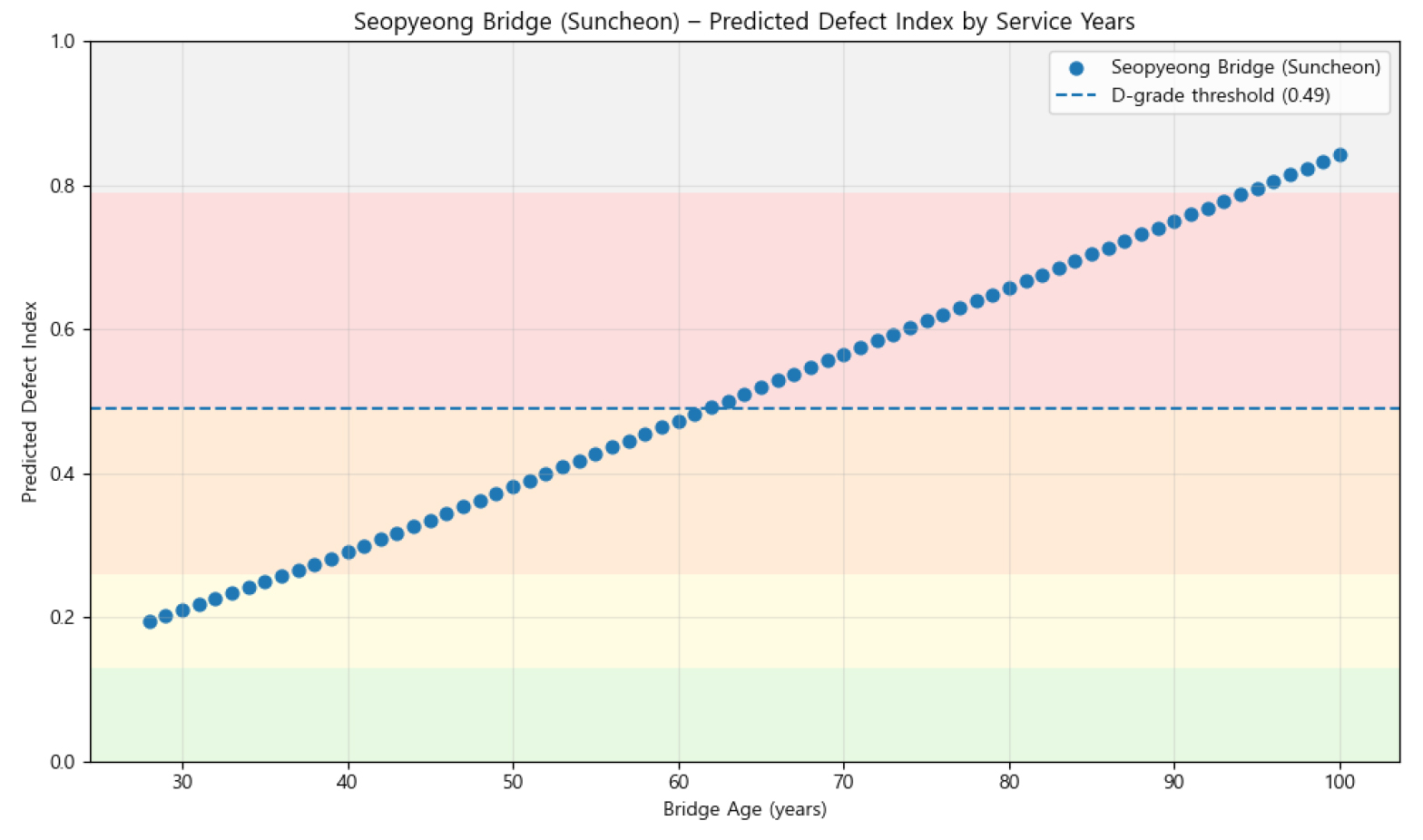
5.3.4 D등급 도달 공용년수 분석
DLN 모델은 XGBoost의 근본적인 외삽 한계를 극복하였다. 4장에서 데이터 증강을 적용한 XGBoost 모델은 전체 9,564개 교량 중 단 6개(0.06%)만 D등급 도달을 예측하여 외삽 구간에서 예측값이 포화되는 한계를 보였다. 반면 DLN 모델은 9,176개 교량이 D등급에 도달할 것으로 예측하여, 단조성 제약을 통해 장기 열화 추세를 물리적으로 타당하게 반영할 수 있음을 실증하였다.
평균 D등급 도달 공용년수는 53년으로, 현재 대비 약 33.9년 후에 도달할 것으로 추정된다. 표준편차 17.0년은 교량별 제원, 환경, 교통 조건에 따른 열화 속도 차이가 현실적으로 반영된 결과이다. 이와 같은 D등급 도달 공용년수의 통계 결과는 Table 13에 정리하였다. XGBoost가 대부분 교량에서 0.22~0.25 수준으로 예측값이 포화되어 획일적인 패턴을 보인 것과 달리, DLN은 교량 고유 특성을 고려한 다양한 열화 경로를 예측하였다
도달 공용년수 범위가 24년부터 100년 이상까지 넓게 분포하여, 가혹한 환경의 교량부터 양호한 상태를 장기간 유지하는 교량까지 현실적으로 구분할 수 있게 되었다. 시뮬레이션 결과, 약 400개 교량(전체의 4.2%)이 100년 내 D등급에 도달하지 않는 것으로 예측되었다. 해당 그룹은 중차량 교통량(ADTT)은 전체 평균의 96.8% 수준으로 유사하나, 평균 염화물 농도는 전체 평균 대비 14.3%(2.70 kg/m³)에 불과하여 극도로 낮게 나타났다.
교량의 급격한 열화는 교통 하중보다 염해에 의한 철근 부식과 콘크리트 손상이 동반될 때 가속화되므로, 본 결과는 염해 영향이 미미한 환경에서 열화 속도가 현저히 느린 것으로 해석된다. 이는 DLN 모델이 염화물 농도가 열화 가속도에 미치는 지배적 영향력을 물리적으로 타당하게 학습하였음을 시사하며, 유지관리 자원의 효율적 배분을 위한 실무적 근거로 활용될 수 있다.
Table 13.
D-Grade arrival service years analysis
| statistic | mean | std. Dev. | Min | 25% | 50% (Median) | 75% | Max |
|
Service Years at D-Grade Arrival | 53 | 17 | 24 | 41 | 48 | 62 | 100 |
5.3.5 DLN 모델의 한계 및 원인 분석
본 연구의 DLN 모델이 물리적으로 기대되는 열화 가속도를 충분히 반영하지 못한 것은 여러 구조적, 기술적 원인이 복합적으로 작용한 결과이다. 첫째, DLN의 선형적 예측은 고결함도 데이터 부족으로 인해 외삽 구간에서 과도한 변동 대신 안정적인 단조 증가 경로를 추정한 결과이다. 이는 실제 열화 가속도를 완벽히 모사하지는 못하나, 일정 수준에서 수렴하여 열화 진행을 멈추는 XGBoost의 비물리적 한계를 극복하고 지속적인 열화 진행을 보장했다는 점에서 의의가 있다.
둘째, 원본 데이터 자체에 명확한 가속 패턴이 존재하지 않는다. 점검 간격이 불규칙하고, 보수 보강 이력으로 인한 결함도지수 감소, 점검자나 평가 시기에 따른 일관성 부족 등으로 인해 실제 증가율 데이터에서 확실한 가속 패턴이 관찰되지 않는다.
셋째, 단조성 제약의 제한적 효과이다. 단조성 제약은 증가율이 줄어들지 않게 할 뿐 증가율이 계속 커지도록 강제하지 않으며, 증가량 모델이기 때문에 공용년수에 대한 증가량의 단조성이 결함도지수 곡선의 가속도와 직접 연결되지 않는다.
넷째, 고결함도 구간 데이터 부족이 결정적인 장애가 된다. 152배 증강으로 샘플을 확대하였으나 Gaussian noise 기반 합성 데이터는 원본 데이터의 통계적 분포를 벗어나지 못하며, 손상 상호작용이나 재료 열화 가속과 같은 새로운 물리적 메커니즘을 도입하지 못한다. DLN의 정규화 메커니즘은 국소적인 급격한 변화를 억제하여 전체 구간에서 비슷한 증가율을 예측하게 만든다. 요약하면, 이는 모델 자체의 결함이라기보다는 데이터 기반 접근법이 가진 근본적인 한계와 현재 사용 가능한 교량 점검 데이터의 특성에서 기인한다.
6. 결 론
본 연구에서는 교량 결함도지수의 장기 예측에서 트리 기반 모델의 외삽 한계를 극복하기 위해 DLN(Deep Lattice Network) 기반 단조성 제약 모델을 개발하였다. 공용년수, 염화물, 교통량 등 주요 변수에 단조성 제약을 적용하여 학습 범위를 벗어난 외삽 구간에서도 물리적으로 타당한 예측을 생성하도록 설계하였으며, 고결함도 구간 데이터 부족 문제를 해결하기 위해 152배 균형잡힌 데이터 증강을 적용하였다. 연구 결과 다음과 같은 결론을 도출하였다.
1) DLN 모델의 단조성 제약은 XGBoost의 외삽 한계를 근본적으로 해결하였다. 원본 DLN 모델은 전체 교량의 99.99%가 평균 공용년수 45년에 D등급에 도달할 것으로 예측한 반면, XGBoost는 0.006%만 예측하고 공용년수 30~40년 이후 포화되었다. 이는 단조성 제약이 학습 데이터 범위를 벗어난 구간에서도 수학적으로 증가를 보장하여 트리 기반 모델의 수렴 현상을 해결하였음을 보여준다.
2) 152배 균형잡힌 데이터 증강은 모델 성능을 획기적으로 개선하였다. 희소 데이터 비중이 0.6%에서 49.9%로 개선되어 전체 데이터의 MAE가 35% 감소하고 MSE도 47% 감소하였다. 희소 구간의 테스트 샘플이 2개에서 273개로 증가하여 통계적 신뢰성이 확보되었으며, 평균 도달 공용년수가 45년에서 53년으로 증가하고 표준편차가 7.3년에서 17.0년으로 확대되어 교량별 특성 차이가 더 현실적으로 반영되었다.
3) 데이터 증강으로 예측 성능이 크게 향상되었으나 열화 가속도를 충분히 반영하지 못하는 한계가 남아있다. 이는 증가량 기반 학습 구조, 원본 데이터의 가속 패턴 부재, 단조성 제약의 한계, 고결함도 실측 데이터 부족 등이 복합적으로 작용한 결과이다. 향후 2차 미분 제약 도입, 물리적 합성 데이터 생성, 실제 고등급 교량 데이터 수집, 모델 앙상블 등을 통해 개선할 필요가 있다.
본 연구는 DLN 기반 단조성 제약 모델과 균형잡힌 데이터 증강의 결합이 교량 열화 예측에서 외삽 문제와 희소 데이터 문제를 동시에 효과적으로 해결할 수 있음을 실증하였으며, 트리 기반 모델의 근본적인 외삽 한계를 극복하는 새로운 방법론적 대안을 제시하였다는 점에서 학술적, 실무적 의의가 크다.
7. 향후 연구 방향
본 연구에서 확인된 열화 가속도 반영의 한계를 극복하기 위해 다음과 같은 연구 방향을 제안한다. 첫째, 단조성 제약으로 인해 보수・보강에 따른 상태 향상(DI 감소)을 반영하지 못하는 한계를 극복해야 한다. 본 연구의 DLN 모델은 공용년수 증가에 따라 결함도가 증가하거나 유지되는 ‘자연 열화’ 과정만을 모델링하였으나, 실제 교량 생애주기에서는 보수 조치를 통해 결함도가 낮아지는 비단조적 현상이 발생한다. 향후 연구에서는 보수・보강 이력을 입력 변수로 추가하거나, 보수 시점을 기준으로 단조성 제약을 재설정하는 방식을 도입하여 유지관리 개입 효과를 모델에 반영할 필요가 있다. 둘째, 공학적 지식 기반 합성 데이터 생성을 통해 고결함도 구간의 실제 열화 패턴을 모사할 수 있다. 셋째, D/E등급 교량의 실제 점검 데이터를 추가 수집하거나 가속 열화 시험 결과를 활용하여 모델의 학습 범위를 확장해야 한다. 넷째, 점검 보고서에서 균열, 박리, 철근 노출 등의 상세 손상정보를 추출하여 열화 모델에 학습시키면 결함도지수만으로는 포착하기 어려운 열화 메커니즘을 반영할 수 있다(Lyu et al., 2025; Nam et al., 2022; Wang and Su, 2023). 다섯째, 마지막으로, DLN, XGBoost, 물리 기반 모델을 앙상블하여 각 모델의 장점을 결합할 수 있다.
본 연구는 DLN 기반 단조성 제약 모델이 XGBoost의 외삽 한계를 극복하고 고결함도 구간 예측 성능을 크게 개선할 수 있음을 실증하였다. 또한, 제시한 연구 방향을 통해 보다 물리적으로 타당한 교량 열화 예측 모델을 개발할 수 있을 것으로 기대된다.
