

1. 서 론
2. 데이터 전처리
2.1 점검 데이터 보완 및 이상치 제거
2.2 변수 추가 및 제거
2.3 데이터 전처리 결과
3. CTGAN 기반 샘플링
3.1 개요
3.2 제약 조건 입력
3.3 CTGAN 적용 결과 및 활용
4. 결 론
1. 서 론
미국, 유럽, 일본 등 주요 선진국들은 산업화에 따른 고도의 경제성장기였던 1950~1990년대에 교량을 비롯한 사회기반시설을 대규모로 확충하였으며, 이 시기에 준공된 교량들의 공용년수가 수십 년이 경과하면서 노후화 문제가 부각되고 있다(Nakashima et al. 2014; Chávez et al. 2024; ASCE 2025). 이러한 교량의 노후화는 교량의 구조적 성능 및 사용성 저하로 이어질 수 있으며, 실제로 2007년 미국 I-35W 교량 붕괴, 2018년 이탈리아 제노바 모란디 교량 붕괴, 2019년 대만 난팡아오 대교 붕괴 등 중대한 교량 붕괴 사고들이 이러한 원인으로 발생하였다. 해당 사례들은 설계수명에 도달했거나 노후화가 진행된 교량에 대한 체계적인 안전점검과 선제적 유지관리의 필요성을 부각시키고 있다.
해외 주요국들은 노후화가 상당 수준 진행 중인 시설이 많으며, 교량 붕괴 사고가 증가함에 따라 국가 차원에서 선제적인 유지관리를 중점적으로 추진하고 있다(NARS 2018). 반면 국내는 아직 국가 주도의 통합적인 유지관리 체계가 정립되지 않았고, 교량을 소유한 각 지자체가 개별적으로 유지관리를 실시하고 있어 사후 대응 중심의 관리가 이루어지고 있다. 이로 인해 관리 시스템의 개발이 미흡하고 현황 입력과 운영 상황 또한 부정확하게 관리되고 있다(Kim and Yoon 2018). 또한, 2018년 “시설물의 안전 및 유지관리에 관한 특별법”(이하 시안법)의 개정에 따라 안전점검 대상 교량이 증가하였으며, 해외보다 짧은 점검 주기에 비해 전문 인력 및 예산의 부족으로 합리적인 점검 및 진단이 어려운 실정이다. 이로 인해 1994년 성수대교 붕괴 이후 교량 유지관리에 대한 중요성이 강조되어 왔음에도 불구하고, 2020년 송정1교 및 동산교 붕괴, 2023년 정자교 붕괴 등 교량 붕괴 사고가 반복되는 결과로 이어졌다. 이로 인해 국내에서도 선제적 교량 유지관리 체계 구축이 시급한 상황이다.
교량의 안전성 및 사용성 확보를 위해서는 안전점검 및 진단 결과인 안전등급에 따른 적절한 보수보강 조치가 필수적이다. 국내에서는 교량의 안전등급을 A(우수), B(양호), C(보통), D(미흡), E(불량)로 구분하며(MOLIT 2024a, 2024b), 이는 교량의 상태 및 내구성을 나타내는 지표로 유지관리를 위한 예산 책정 및 보수보강 계획의 수립을 위한 중요한 기준이 된다. 그러나, 일부 교량에서는 점검의 부실 또는 점검 시기 미준수 등의 이유로 안전등급의 산정이 어렵거나 불확실한 경우가 존재한다. 또한, 안전등급을 산정하더라도 향후 노후화로 인해 결함 발생이 예상되는 교량을 조기에 식별하지 못하면 시의적절한 보수보강 계획 수립이 어렵다는 한계가 있다. 이에 따라 실제 점검을 수행하지 않더라도 교량의 상태를 추정하거나 노후화 가능성이 존재하는 교량을 미리 식별하여 점검 체계의 효율성 및 경제성을 확보하는 방안으로 인공지능 및 확률론적 방법이 도입되고 있다(Kobayashi et al. 2012; Bektas et al. 2013; Kim and Queiroz 2017; Lee et al. 2018; Assaad and El-Adaway 2020; Lei et al. 2022; Jayathilaka et al. 2023).
이처럼 교량의 안전등급을 예측하고 교량 유지관리에 활용하기 위하여 Chung et al.(2016)은 A와 B등급은 G(Good)로, C등급 이하 교량은 P(Poor)로 구분하여 이진분류를 통해 예측하였다. 그러나 B등급은 A등급과 달리 결함이 존재하여 유지관리가 필요함에도 A등급과 동일군으로 취급 시 유지관리 의사결정에 필요한 민감도가 저하될 수 있다. 이에 따라 Hong and Jeon(2023, 2025)은 A, B, C&D등급으로 다중분류하도록 머신러닝 모델을 적용하였으며, 등급의 불균형 문제를 완화하기 위해 Random oversampling, Random undersampling, SMOTE(Synthetic Minority Over-sampling Technique)Tomek sampling과 같은 전통적 샘플링 기법을 적용하였다. 그러나 이러한 기법은 데이터 분포만을 조정하는 방식으로 변수 간 상호작용을 충분히 반영하지 못하고, A등급과 C&D등급 사이의 중간 특성을 갖는 B등급의 정보가 손실되어 예측 성능이 저하되는 현상이 발생하였다. 이에 따라 인공지능 학습에 적합하도록 교량 데이터의 특성을 효과적으로 학습할 수 있는 새로운 방안이 필요하였다.
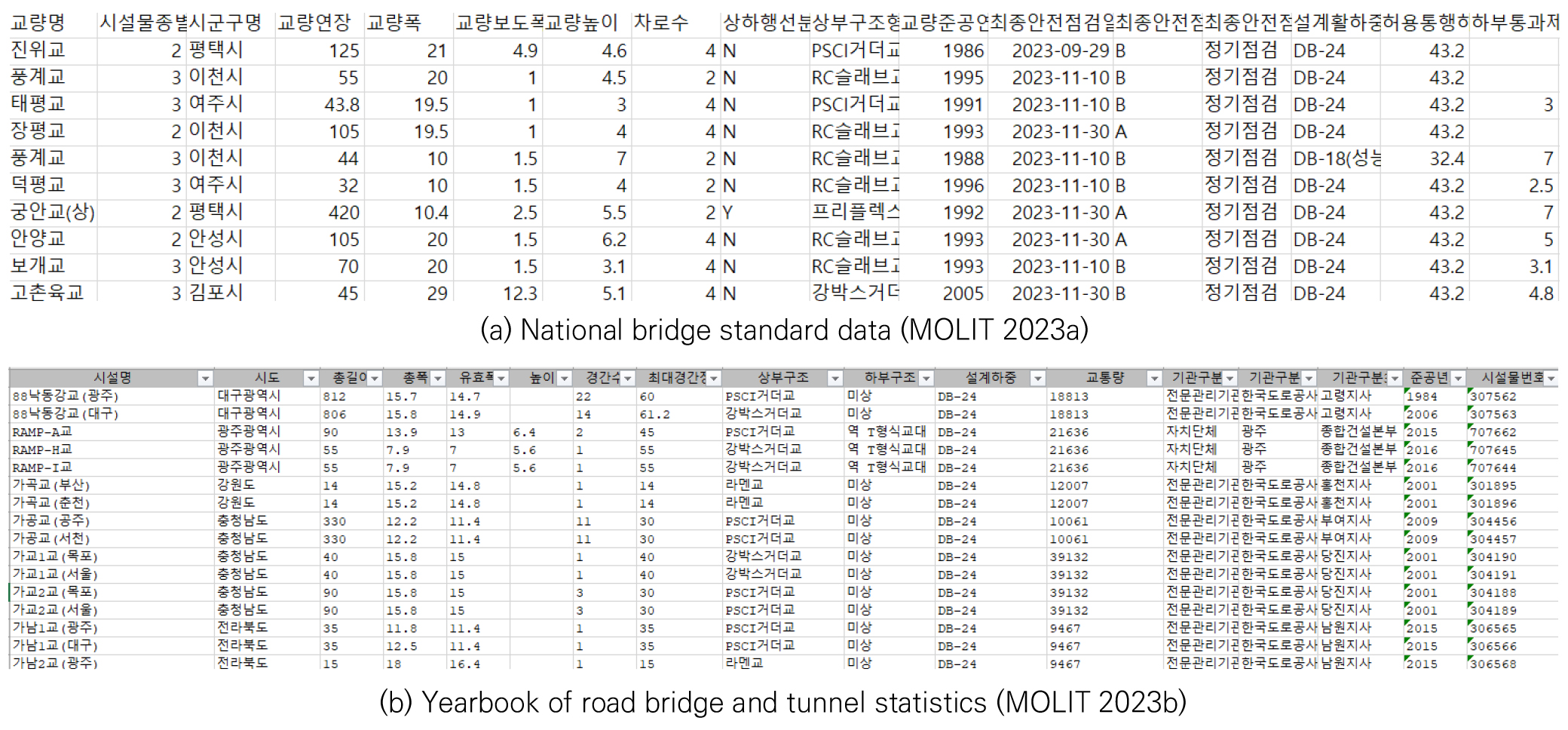
그러나, 국내의 교량 안전등급 관련 데이터는 Fig. 1의 전국교량표준데이터(2023), 도로 교량 및 터널 현황 조서(2023)와 같이 범주형과 수치형 변수가 혼재된 표 형식의 데이터로, 시계열 데이터나 이미지 생성에 주로 활용되는 GAN(Generative Adversarial Networks), Transformer, Diffusion 모델과 같은 일반적인 딥러닝 기반 생성기법으로 데이터를 보완하는 방식을 직접 적용하기 어렵다. 이러한 제약으로 인하여 교량 관련 표 데이터를 대상으로 한 생성 기반 연구는 거의 수행되지 않았으며, 부재별 상태등급에 대하여 GAN을 적용한 사례가 존재하나 표 형식에 최적화되지 않아 성능이 다소 낮았다(Bayat and Kharel 2025).
따라서, 이 연구에서는 표 형식의 데이터를 생성할 수 있는 기법인 CTGAN(Conditional Tabular GAN)을 도입하여 불균형한 데이터를 보완하고, 교량 안전등급 예측 모델의 성능 향상을 위한 기반을 마련하고자 하였다. Fig. 2는 이 연구에서 CTGAN을 적용하고 그 효과를 비교하는 방법론을 요약하여 나타내었다.

2. 데이터 전처리
CTGAN 기반 샘플링 및 인공지능 기반 분류 모델의 구축을 위해서는 학습에 사용하는 데이터의 신뢰성과 설명력을 확보하는 전처리 과정이 필수적이다. 특히 실제 데이터의 특성과 유사한 합성 데이터를 생성하기 위해서는 원 데이터의 품질을 향상시킬 수 있는 데이터 전처리를 수행해야 한다.
2.1 점검 데이터 보완 및 이상치 제거
이 연구에서는 전국교량표준데이터(MOLIT 2023a)를 활용하여 교량의 안전등급 예측을 수행하였다. 그러나 해당 데이터는 주로 정기안전점검 결과를 기반으로 작성되어 있어, 교량의 상태 및 내구성 반영의 정확도가 비교적 높은 정밀안전점검 및 정밀안전진단의 결과로 대체해야 할 필요가 있다. 따라서 이를 보완하기 위해 시설물통합정보관리시스템(FMS 2023)과 도로 교량 및 터널 현황 조서(MOLIT 2023b)에서 추가적으로 안전점검 및 진단 정보를 수집하였다. Fig. 3와 같이 확보된 자료를 바탕으로 정기안전점검보다 정확도가 높은 정밀안전점검 및 정밀안전진단 결과를 우선적으로 반영하여 데이터를 수정하였다. 그러나 비교적 최근에 준공되어 정밀안전점검 및 정밀안전진단 결과가 없는 교량의 경우에는 기존의 정기안전점검 결과를 사용하였다.

한편 교량 안전등급 데이터의 신뢰성을 확보하기 위해 보수보강 이력과 안전등급 변동 기록에 대한 추가적인 검증 절차를 수행하였다. 먼저 최근 보수보강 활동 이후 경과기간을 살펴본 결과, 일부 교량에서는 보수보강 경과기간이 비정상적으로 길어도 A등급으로 판정된 사례가 존재하였다. 이러한 경우는 안전점검의 형식적 이행 또는 기록 오류 가능성이 크다고 판단하여, IQR (InterQuartile Range)을 이용한 이상치 기준에 따라 해당 데이터를 제거하였다. 또한, 안전등급 변경 사유 여부를 활용하여 안전등급 변동의 합리성을 검토하였다. 예를 들어 C등급에서 B등급으로 상향되기 위해서는 보수보강 조치가 필수적이나, 실제 보수보강이 수행되지 않았음에도 등급이 상향된 사례가 일부 존재하였다. 이러한 경우는 점검 기록의 누락 및 비정상적인 등급 산정이 이루어진 것으로 판단하여 데이터를 제거하였다. 이처럼 정밀안전점검 및 진단 데이터의 안전등급 결과 반영 및 데이터 이상치 제거를 통하여 전국교량표준데이터의 신뢰성을 확보하고자 하였다.
2.2 변수 추가 및 제거
전국교량표준데이터는 교량 형식, 연장, 폭 등 기본 제원을 중심으로 구성되어 있어서 실제 안전등급 산정에 중요한 영향을 미칠 수 있는 운영·관리 정보가 일부 제외되어 있다. 특히 점검 이행 수준, 보수보강 활동, 결함 발생 특성과 같이 유지관리의 질이나 환경적 특성을 반영하는 변수는 안전등급과 높은 연관성을 가질 수 있음에도 데이터에 포함되어 있지 않다. 이에 따라 시설물통합정보관리시스템(2023)의 점검 및 진단 이력을 활용하여 다음과 같은 변수를 추가하였다.
먼저, 점검 이행 수준을 반영하기 위해 점검 시기 미준수 여부를 변수로 포함하였다. 점검 주기가 기준보다 지연된 경우는 관리 주체의 유지관리 수준이 낮음을 의미할 수 있으며, 이는 교량 노후화와 직결될 수 있어 안전등급 예측에 중요한 요인으로 판단하였다.
또한, 보수보강 활동의 정도를 반영하기 위해 보수보강 횟수를 변수로 추가하였다. 보수보강 횟수는 유지관리 활동의 정도를 나타내는 지표로서 보수보강이 적절하게 이루어진 경우 유지관리가 체계적으로 이루어진 것으로 해석할 수 있으나, 보수보강 횟수가 과도하게 많을 경우 반대로 반복적인 결함 발생이나 사용성 저하 가능성을 의미할 수도 있다.
추가적으로 결함 발생 특성과 환경적 노출 조건을 고려하기 위해 중대 결함 횟수, 교량별 평균일교통량, 교량 위치 특성을 변수로 반영하였다. 중대 결함은 주로 C등급 이하 교량에서 발생하는 특성이 있어 안전등급과의 연관성이 높고, 평균일교통량은 교통하중으로 인한 피로 작용에 따른 손상 가능성을 나타내는 중요한 변수이다. 또한 탄산화 및 염해는 환경적 열화에 큰 영향을 미치므로, 교량 위치 변수를 추가하여 탄산화 영향 지역, 염해 영향 지역, 기타 지역으로 구분하였다. 공업단지 및 산업단지는 탄산화 지역으로, 해안가 인접 지역은 콘크리트표준시방서 해설(KCI 2009)을 참고하여 염해 지역으로 분류하였다. 이와 같이 기존 교량 제원만으로는 설명하기 어려웠던 유지관리 수준과 환경적 요인을 보완하여 안전등급 예측의 정확도를 향상시키고자 하였다.
반면, 변수가 과도하게 많은 경우 인공지능 모델의 학습 안정성 및 성능 저하를 유발할 수 있다. 이에 따라 Hong and Jeon(2023; 2025)의 기존 연구와 유사하게 변수 제거 및 변수 축소 과정을 수행하였다. 먼저, 식 (1)과 같이 피어슨 상관계수를 도출하여 수치형 변수들의 상관관계를 산출하고 높은 상관성을 가지는 변수는 제거하였다. 피어슨 상관계수의 경우 1 또는 –1에 가까울수록 상관관계가 크고, 0에 가까울수록 상관관계가 낮다. 일반적으로 절대값이 0.7 이상이면 강한 상관관계를 가졌다고 판단하기 때문에, 0.7 이상인 변수들은 적절한 한 개의 변수만을 존치시켰다.
여기서, =피어슨 상관계수, =각 변수의 관측값, =각 변수의 평균.
또한, 이 연구에서는 다수의 범주형 변수들이 추가되었기 때문에, 범주형 변수 간 상관관계를 평가하기 위하여 식 (2)와 같은 Cramér’s V를 적용하였다. 일반적으로 0.5 이상은 강한 상관성을 나타내므로, V 값이 0.5 이상인 범주형 변수들은 적절한 한 개의 변수만을 존치시켰다.
여기서, =Cramér’s V 값, =카이제곱 통계량, =표본 크기, =범주형 변수의 열, =범주형 변수의 행.
추가적으로 수치형 변수와 범주형 변수가 혼재된 데이터의 다중공선성을 산출할 수 있는 분산팽창계수(Variance Inflation Factor: VIF) 값을 식 (3)과 같이 도출하였다. 일반적인 경우와 같이 VIF 값이 10 이상인 변수는 다중공선성이 높다고 판단하여 제거하였다. 이 과정에서 기존 연구(Hong and Jeon 2023; 2025)와 달리 설계활하중 변수가 다른 변수와 높은 상관성을 나타내어 최종 변수에서 제외되었다.
여기서, =변수 의 분산팽창계수, =변수 를 종속변수로 설정하고 나머지 변수를 독립변수로 설정하는 회귀모형의 결정계수.
2.3 데이터 전처리 결과
데이터 전처리 과정 이후 최종적으로 사용된 변수는 Table 1에 정리하였으며, 전체 일반국도 교량 8,843개 중 총 4,655개의 데이터가 모델 구축에 활용되었다. 전처리 이전 원시 데이터의 안전등급 분포는 A등급 4,849개, B등급 3,553개, C&D등급 441개로 A등급과 B등급의 개수 차이가 작았다. 그러나 전처리 과정에서 이상치 및 결측치로 판단된 교량 데이터가 제거되면서 안전등급 분포의 불균형이 전처리 이전보다 크게 심화되었다. 그 결과, 최종 데이터셋의 안전등급 분포는 A등급 36개, B등급 3,893개, C&D등급 726개로 나타났다. 특히, A등급과 C&D등급의 데이터 수가 매우 적어 전체적으로 심각한 불균형 분포가 발생하였다.
Table 1.
Selected variables
3. CTGAN 기반 샘플링
3.1 개요
최근 데이터 보완 기법으로 GAN, VAE, Diffusion 모델과 같은 딥러닝 생성 모델을 많이 활용하고 있다. 이는 전통적 샘플링 기법이 학습하기 어려웠던 변수 간 상호작용을 학습하여 실제와 유사하지만 다양하고 풍부한 데이터를 생성할 수 있는 장점이 있다. 그러나 표 형식의 데이터의 경우 범주형 데이터와 수치형 데이터가 혼재되어 있으며, 이러한 특성은 기존의 딥러닝 기반 생성 모델을 적용하는 데 제약 사항이 될 수 있다.
즉, 이미지나 시계열 데이터들은 수치형으로 표현하면 가우시안(Gaussian) 분포와 유사하기 때문에 정규화할 수 있으나, 표 형식의 수치형 데이터의 경우 대부분 가우시안 분포를 따르지 않아서 최적화 함수 적용 시 기울기 소실 문제로 실제와 유사한 데이터 생성이 어렵다는 문제가 존재한다. 또한 범주형 분포의 경우에는 일반적인 합성 데이터 기법들이 연속형 변수 기반의 손실함수와 구조를 사용하도록 설계되어 있어, 범주형 변수의 고유값의 빈도를 모사하지 못한다. 이로 인해 데이터의 다양성을 반영하지 못하고 최대 빈도의 고유값만 반복적으로 생성하는 모드 붕괴 문제가 발생할 수 있다. 따라서, 기존의 딥러닝 기반 생성 모델을 그대로 적용할 경우 데이터 다양성이 확보되지 않고, 생성 품질 또한 크게 저하되는 문제점이 있다.
이와 같은 문제를 극복하기 위하여 CTGAN은 데이터를 생성하는 생성자 및 실제와 합성 데이터의 유사성을 판별하는 판별자가 경쟁하는 GAN 구조를 바탕으로 실제와 유사한 데이터를 합성할 수 있으면서도, 표 형식에 적합하게 특화된 구조를 도입하였다. 먼저 Fig. 4(a)와 같이 GMM(Gaussian Mixture Model)을 활용하여 가우시안 분포를 따르지 않고 Multi-modal 형태가 나타나는 수치형 변수를 가우시안 분포가 혼합된 형태로 변환함으로써, 수치형 변수를 안정적으로 생성하면서도 Multi-modal의 형태와 유사하게 생성할 수 있도록 한다. 또한, 범주형 분포의 경우 One-hot encoding을 대체하는 Conditional generator 구조를 도입하여, Fig. 4(b)와 같이 범주형 변수의 각 고유값을 희소값이 아닌 조건부 확률로 학습하도록 설계되어 범주형 분포의 빈도 특성을 보다 정확하게 반영할 수 있다(Xu et al. 2019).
이 연구에서는 교량 안전등급의 불균형 분포를 고려하여 A등급 및 C&D등급을 중심으로 CTGAN 기반 샘플링을 수행하였다. A등급과 C&D등급은 전체 데이터에서 매우 적은 비율을 차지하는 소수 클래스로, 인공지능 모델을 적용하면 학습이 충분히 이루어지지 않아 성능이 저하되는 결과가 발생한다. 그러나 전통적 샘플링 기법 중 Random undersampling을 적용하면 다수 클래스인 B등급의 데이터가 크게 감소하여 B등급의 특성이 제대로 학습되지 못하고, Random oversampling을 적용하면 소수 클래스의 분포를 복제하게 되어 과적합이 나타나는 문제가 발생한다. 특히 B등급은 A등급과 C&D등급 사이의 중간적 특성을 지니고 있어, 데이터가 유실될 경우 등급 간 경계가 더욱 모호해지는 문제가 있다. 따라서, 이 연구에서는 A등급 및 C&D등급의 실제 특성을 반영한 합성 데이터를 생성함으로써 소수 클래스의 학습 여력을 확보하고, 동시에 B등급의 원본 데이터를 유지하여 중간 등급의 특성도 충분히 학습되도록 하였다. 이를 통해 안전등급의 불균형 분포를 개선하고, 교량 안전등급 예측 모델의 전반적인 성능 향상을 도모하였다.
3.2 제약 조건 입력
CTGAN은 본래 확률적 생성 모델로서, GAN과 같이 노이즈를 활용하여 데이터를 생성하기 때문에 학습된 분포를 기반으로 데이터를 생성하더라도 실제 데이터의 규칙이 위반되는 경우가 있다. 즉, 원 데이터에 존재하지 않아야 할 변수 조합이 합성 데이터로 생성될 가능성이 존재한다. 이러한 문제를 해결하기 위해 CTGAN은 사용자가 사전에 규정한 제약 조건을 반영하여 비현실적 데이터 생성을 방지할 수 있다.
이 연구에서도 교량 안전등급과 유지관리 이력 간의 관계를 고려했을 때, 반드시 충족해야 하는 규칙이 존재하였다. 예를 들어, 보수보강 활동이 한 번도 수행되지 않은 교량의 경우 보수보강 경과기간이 존재할 수 없다. 이에 따라 보수보강 횟수가 0인 교량은 보수보강 경과기간을 ‘None’에 해당하는 값으로 처리해야 한다. 만약 제약 조건을 입력하지 않을 경우, 확률적 생성 특성으로 인해 보수보강 이력이 없음에도 보수보강 경과기간이 존재하는 비합리적인 데이터가 생성될 수 있다.
따라서, 이 연구에서도 제약 조건 입력을 통하여 교량 데이터가 갖추어야 할 도메인 지식 기반의 규칙을 명시적으로 반영하였다. 이를 통해 합성 데이터의 일관성을 확보하고, 실제 데이터의 구조적 특성을 유지하면서도 신뢰도 높은 표 형식의 데이터를 생성할 수 있음을 확인하였다.
3.3 CTGAN 적용 결과 및 활용
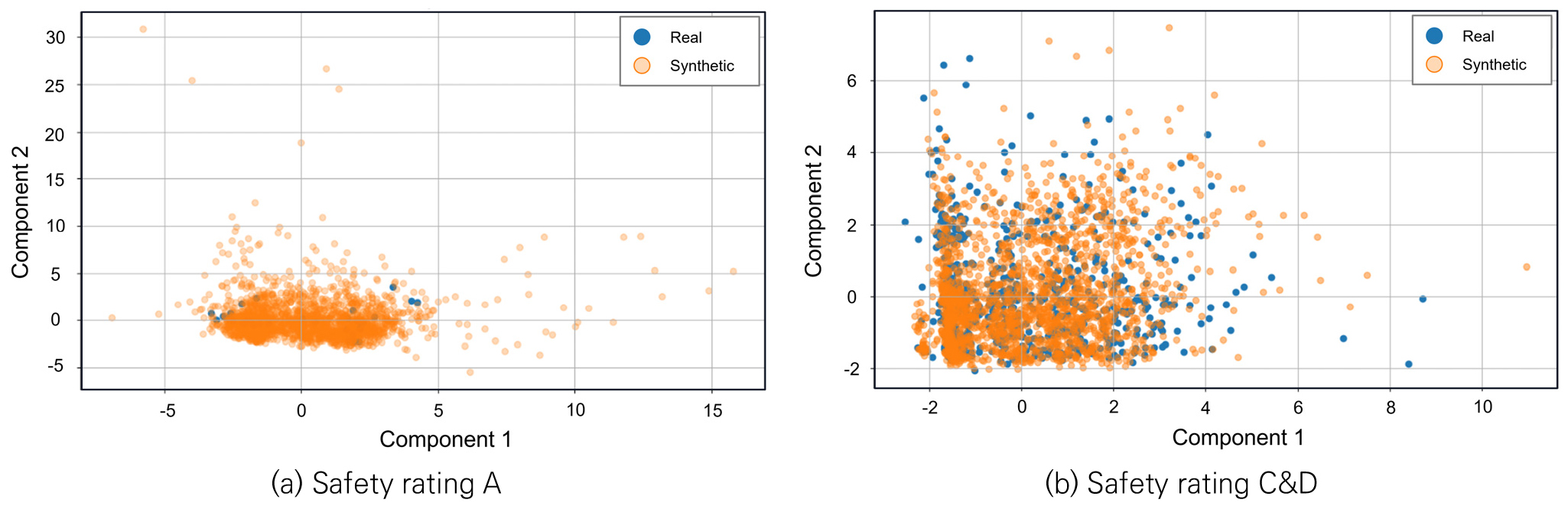
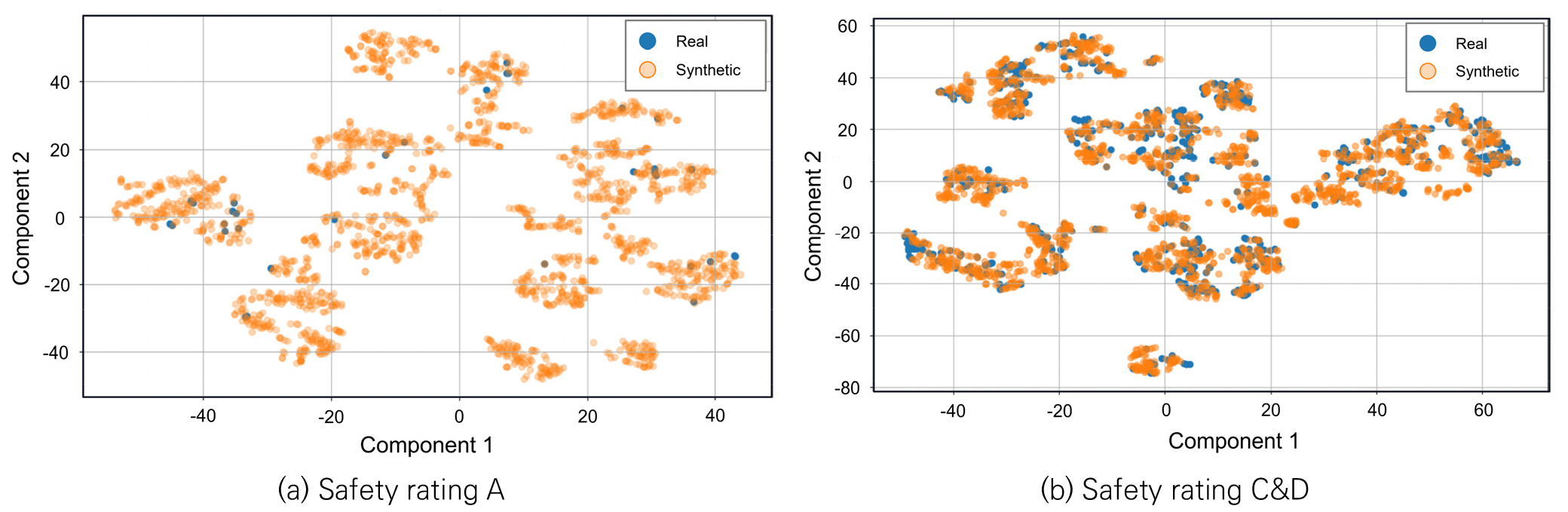
CTGAN의 합성 데이터와 실제 데이터의 구조적 특징의 유사성을 확인하기 위하여, PCA(Principal Component Analysis) 및 t-SNE(t-distributed Stochastic Neighbor Embedding) 기반의 차원 축소 분석을 수행하여 실제 데이터와 합성 데이터를 동일한 저차원 공간에 투영하였다.
PCA는 데이터의 분산이 가장 큰 방향으로 주성분을 도출하는 선형 차원 축소 기법으로 데이터의 전역적 구조를 파악하는 데 유용하다(Maćkiewicz and Ratajczak 1993). Fig. 5에 제시된 A등급과 C&D등급의 PCA 결과와 같이, 두 등급 모두에서 합성 데이터는 실제 데이터가 형성하는 분산 구조와 주성분 방향을 재현하였다. 즉, 합성 데이터는 실제 데이터와 동일한 주성분 공간 내에 분포하며, 제 1 및 2 주성분 축을 따르는 분산 범위가 실제 데이터의 분산 범위와 유사한 수준으로 유지되었다. 이는 합성 데이터가 실제 데이터의 주요 변동 방향과 상대적 분산 규모를 재현하고 있음을 의미한다. 특히 A등급의 경우 데이터 수가 매우 적음에도 불구하고, 합성 데이터에서 과도한 분산 증가나 군집 왜곡이 발생하지 않은 것을 확인할 수 있었다.
t-SNE는 데이터 간의 상대적 거리를 계산하여 비선형 차원 축소를 수행함으로써 고차원 데이터의 국소적 구조를 시각화할 수 있다(Maaten and Hinton 2008). Fig. 6의 시각화 결과에서 두 등급 모두 실제 데이터와 합성 데이터는 동일한 군집 내에 위치하여 국소적 구조에서도 유사하다는 것을 확인할 수 있었다. 이때, 합성 데이터는 실제 데이터가 형성한 군집의 중심 및 고밀도 영역을 중심으로 분포하였다. 또한, 특정 군집만 과도하게 확장되거나 축소되는 현상도 관찰되지 않았으며, 이는 CTGAN 샘플링이 복잡한 비선형 구조를 가진 실제 데이터의 근접 관계를 효과적으로 모사했음을 의미한다.
제안된 CTGAN 샘플링 방법의 효용성을 검증하기 위해 통상적인 랜덤포레스트 분류 모델을 사용하여 교량 안전등급을 예측하여 보았다. 이때, 전통적 샘플링 기법 중 하나인 Random undersampling을 적용했을 때에는 B등급 재현율 49.4%로 무작위 예측 수준인 50%에도 미치지 못하였고, A등급에 과적합되는 결과를 나타내었다. 반면 CTGAN 기반 샘플링을 적용한 경우에는 B등급 재현율이 76.5%로 크게 향상되었으며, A등급과 C&D등급 또한 모두 50% 이상의 재현율을 확보하였다. 이는 소수 클래스에 대한 학습 데이터를 확보함과 동시에 B등급의 원본 데이터를 유지하여 B등급 학습 성능 저하를 방지한 결과로 해석된다. 향후 분류 모델의 하이퍼파라미터 튜닝을 통해 예측 성능을 추가적으로 개선할 여지가 있다. 이처럼 CTGAN 기반 샘플링은 범주형 및 수치형 변수가 혼재된 표 형태의 교량 안전등급 데이터 환경에서도 실제 데이터의 구조적 특성을 효과적으로 재현하며, 전통적 샘플링 기법 대비 우수한 학습 데이터 품질을 제공할 수 있을 것으로 기대된다.
다만, 이 연구에서는 교량의 안전등급 데이터의 신뢰성을 확보하고 점검 과정에서 발생할 수 있는 주관적 영향을 최소화하기 위해 보수보강 이력 및 안전등급 변동 기록을 활용하였으나, 안전등급 자체가 점검자의 판단에 기반한 결과라는 점에서 주관적 불확실성이 완전히 배제되었다고 보기는 어렵다. 따라서, 향후에는 교량 안전등급 산정의 신뢰성에 대한 정량적 분석과 함께 주관적 불확실성을 고려한 데이터 정제 및 모델링 기법을 연구함으로써 예측 결과의 해석 가능성과 활용성을 더욱 향상시키는 것이 바람직하다.
상기의 예시와 같이 이 연구에서 제시한 기법으로 확보한 양질의 교량 데이터는 기존 연구(Hong and Jeon 2023; 2025)에서 나타난 B등급 교량의 정보 손실 문제를 크게 저감하여 교량 안전등급 예측 성능을 개선하는 데 기여할 수 있다. 특히 B등급 교량은 구조적 상태가 양호한 교량과 열화가 진행 중인 교량의 경계에 위치하여 유지관리 의사결정 과정에서 명확한 판단이 어려운 등급이다. 이러한 특성으로 인해 B등급 재현율이 낮을 경우, 실제로 관리가 필요한 교량이 A등급으로 상향 예측되어 점검 대상에서 누락되거나 적절한 유지관리 시기를 놓칠 가능성이 존재한다. 따라서, B등급 재현율의 향상은 유지관리 우선순위 결정의 신뢰성을 확보하고, 불필요한 유지관리 비용 증가 및 관리 대상 누락을 방지하는 데 중요한 의미를 갖는다. 또한, 교량 안전등급 예측 성능의 향상은 교량 유지관리와 관련하여 노후화가 크게 진행된 것으로 예측되어 긴급한 점검이나 진단이 필요한 교량을 선별하는 등 유지관리 계획 및 예산 수립에 유용하게 활용될 수 있을 것으로 생각된다.
4. 결 론
이 연구에서는 인공지능 기반 교량 안전등급 예측 성능을 향상시킬 방안을 마련하기 위하여, 국내 교량 안전등급 데이터의 전처리 과정 및 데이터의 불균형 분포를 해결하기 위한 방법을 제시하였다. 이를 위해 정밀안전점검 및 진단 결과의 반영, 유지관리 이력 및 환경적 특성의 보완, 이상치 제거 및 변수 축소 등 데이터 품질 향상을 위한 전처리 절차를 구축하였으며, 소수 등급의 분포를 효과적으로 보완하기 위해 신뢰성 높은 합성 데이터를 생성하는 기법인 CTGAN 기반 샘플링을 적용하였다. 이 연구에서 도출된 주요 결론은 다음과 같다.
1) 교량 안전등급 데이터의 신뢰성 확보를 위해 전처리 과정에서 정밀안전점검 및 정밀안전진단 결과를 우선적으로 반영하였으며, 보수보강 이력, 점검 시기 준수 여부, 안전등급 변경의 타당성 등을 검토하여 이상치로 판단되는 데이터를 제거하였다. 또한 유지관리 이력 및 환경 특성과 관련된 주요 변수를 추가하여 교량 안전등급 예측에 영향을 미치는 주요 요인을 포함함으로써 인공지능 모델 학습에 적합한 교량 데이터를 도출하였다.
2) 제안된 CTGAN 기반 샘플링 기법은 교량 안전등급 데이터가 특정 등급에 편중된 불균형 구조를 보완하기 위해 적용되었으며, PCA와 t-SNE 기법을 통한 시각적 분석 결과 소수 등급인 A등급 및 C&D등급의 분포를 실제 데이터의 특성과 유사하게 재현하는 합성 데이터를 생성하는 것으로 확인되었다. 제안된 기법의 검증을 위해 랜덤 포레스트 기법으로 교량 안전등급을 예측해 보았으며, 이때 전통적 샘플링 기법을 적용할 경우 B등급 재현율이 50% 이하로 무작위 예측 수준에 머물렀던 반면, CTGAN 기반 샘플링은 B등급 재현율이 76.5%로 B등급 예측 성능 저하 현상이 발생하지 않았다. 추후 연구에서는 생성된 데이터에 대한 통계적 분석을 통하여 타당성을 추가로 검증하고, 이를 기반으로 교량 안전등급 예측 모델의 성능을 더욱 향상시켜 교량 유지관리 분야에 활용하고자 한다.
3) 제안된 기법을 통해 확보한 양질의 교량 데이터는 교량 안전등급 예측 성능 개선 외에도 긴급한 점검이나 진단을 요하는 노후 교량의 선별 등 교량 유지관리 계획 및 예산 수립에 유용하게 활용될 수 있을 것으로 생각된다.
